Voici la suite de notre mini-lexique dédiée aux personnes non professionnelles du web qui souhaitent en savoir plus sur le web scraping.
 +336 67 57 33 79
+336 67 57 33 79
12
fev
Les 8 concepts clés que vous devez maitriser si vous débutez dans le web scraping (Partie 2)
5 - Front-end / Back-end

Vous avez aussi dû souvent entendre parler du tandem client/serveur ou navigateur/serveur. Tous ces termes désignent la même chose. Pour que tout cela vous semble plus clair, vous devez comprendre que les sites et applications web sont séparés en deux parties :
- La partie front-end, ou client, désigne ce qui est avant tout visible par l’internaute qui navigue sur le site en question. Pour faire une comparaison simpliste, c’est l’équivalent de la vitrine pour un commerce. Les 3 piliers constituant la partie front-end d’un site web à l’heure actuelle sont le code HTML, le CSS, et le JavaScript. Le HTML définit gérant la structure du site et la disposition des différents éléments visibles. Le code CSS établit les règles de style : couleurs, polices, taille des différents éléments. L’apparence « esthétique » du site dépend donc du code CSS. Enfin, le code JavaScript s’occupe, en partie, de gérer les interactions et événements dynamiques : évènements se déclenchant au click sur un élément, apparition ou disparition d’un élément, gestion d’appels AJAX…). Ces langages sont interprétés par le navigateur web utilisé par le visiteur. Et oui, vous ne le soupçonniez peut être pas, mais ces fameux navigateurs web que vous utilisez chaque jour, qu’il s’agisse de Google Chrome, Mozilla Firefox, Safari ou autres, ont tous la faculté de comprendre les codes HTML, CSS, ainsi que le langage JavaScript. Il n’est par contre pas possible de leur faire interpréter des langages de type « serveur », comme le PHP, le Python, ou encore le Java.
- La partie back-end, ou serveur, désigne l’arrière boutique. Chaque site web est hébergé sur ce qu’on appel un serveur. La partie back-end désigne tout ce qu’il se passe du côté du serveur. Pour vous donner un exemple, lorsque vous vous authentifiez sur un site sur lequel vous disposez d’un compte, vous remplissez un formulaire de connexion. Ce formulaire, en termes d’apparence esthétique, est un élément « front-end », crée avec du code HTML et CSS interprété par le navigateur. Par contre, lorsque vous validez ce formulaire, votre identifiant et votre mot de passe sont envoyés vers un fichier situé coté back-end (sur le serveur donc). Ce fichier va aller vérifier dans la base de données (située elle aussi sur le serveur) s’il existe un utilisateur qui correspond aux informations que vous avez fournies. La logique est exactement la même que dans une boutique ou un restaurant, pour reprendre la métaphore précédente : à la réception (l’équivalent du front) quelqu’un prend votre commande, et dans l’arrière boutique (côté back) quelqu’un s’occupe de la préparer.

Vous avez ici une description schématique de comment fonctionne le web « traditionnellement ». De nos jours, l’innovation technologique qu’à connu l’univers front-end a amené de la nouveauté. De plus en plus de choses sont désormais gérées côté front. De nouvelles technologies front sont apparues et ont clairement étendues le champ des possibles (en particulier les fameux frameworks JavaScript tels qu’Angular, React, Vue, etc). Le travail effectué côté navigateur est clairement plus conséquent qu’auparavant. Ainsi, de plus en plus de sites délèguent un nombre croissant de fonctionnalités au navigateur, y compris parfois la génération du contenu textuel. C’est précisément ce point qui nous intéresse dans le cadre du web scraping. Comme nous l’avons vu dans notre méthodologie préalable au web scraping, la première chose que nous devons essayer de comprendre lorsque l’on cherche à scraper un site est de savoir si la donnée que nous convoitons est générée dynamiquement côté navigateur, ou si elle est générée statiquement coté serveur. Et, après avoir lu cette méthodologie, vous comprendrez à quel point la réponse à cette question va influer sur notre façon de réaliser notre web scraping…

6 - Headless-browser
Il s’agit d’un navigateur web sans interface graphique. Quel intérêt d’utiliser un navigateur web si on ne peut même pas voir ce qu’il se passe dessus ? Dans le domaine du web scraping, l’utilisation du headless-browser a un intérêt capital. En lien avec ce que nous avons vu dans le point précédent, ainsi que tout ce que nous avons expliqué dans notre méthodologie, le travail de web scraping que nous allons mener n’est pas le même en fonction de la façon dont est générée la donnée que nous voulons récupérer. La plupart des outils de web scraping existant fonctionnent d’une façon simple : une requête est envoyée en direction de la page web visée, on récupère le contenu html renvoyé par le serveur, et on va ensuite fouiller dans ce code ce qui nous intéresse. Ainsi, le code récupéré avec ces outils est semblable à ce que l’on récupère lorsqu’avec n’importe quel navigateur, nous cliquons sur « Afficher le code source ».
Ainsi, si la donnée que nous souhaitons récupérer est générée dynamiquement côté front, elle n’apparaitra pas dans le code source. Ce qui veut dire que le contenu que l’on aura récupéré avec notre outil classique de web scraping ne nous permettra pas de mettre la main sur ces fameuses informations… Dans ce cas, l’utilisation d’un outil de web scraping utilisant un headless-browser est la solution dont nous avons besoin. Ici, l’outil en question ne va pas émettre une simple requête afin de récupérer le contenu HTML brut. Par le biais du headless-browser qu’il va lancer, il va simuler une navigation réelle, comme s’il était dans la peau d’un être humain se connectant à une page web via un navigateur lambda. Ainsi, plutôt que d’aller fouiller dans le code HTML statique, il vous donnera la possibilité d’aller fouiller dans le contenu dynamique de la page. Ce qui, au passage, vous donnera donc la possibilité d’effectuer des interactions avec le site en question (scroll, click, changement de pages, etc). L’avantage est donc que vous avez la possibilité d’accéder à toutes les infos visibles sur le site. L’inconvénient, dans le cadre d’un travail de web scraping, est que cette façon de fonctionner demande plus de temps de traitement, et que votre scraping sera donc ralentit.
Parmi les librairies de web scraping basées sur un headless-browser, nous pouvons citer :
- Puppeteer (Nodejs)
- Selenium (Python)
- Kimura (Ruby)
7 - Sélecteur CSS
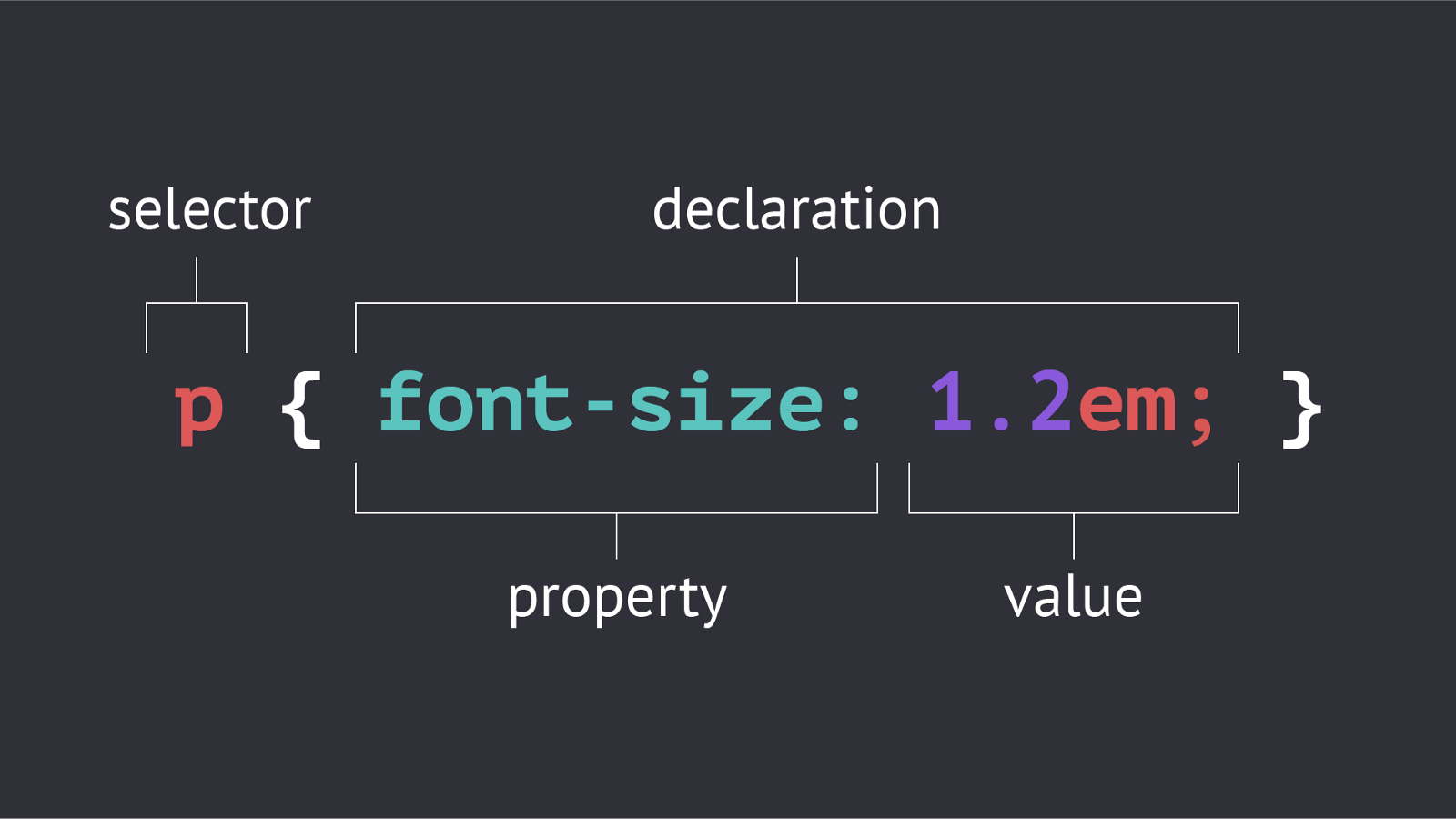
Avant toute chose, on va s’assurer que tout le monde comprenne bien ce dont on parle. Pour ceux qui ne le sauraient pas, le CSS est un langage de feuilles de styles. Pour le dire plus simplement, c’est le langage qui gère la mise en forme d’un site web. Contrairement aux langages de programmation (PHP, C++, Node…) qui sont multiples, le CSS est le seul et unique langage utilisé pour créer des feuilles de style (nous rappelons que le Saas ou le Less ne sont que des déclinaisons ou des surcouches basées sur le CSS). La personne qui rédige un fichier CSS va définir des règles de style et de mise en forme pour les différents éléments HTML qu’il souhaite retoucher (blocks, zones de texte, titres, formulaires, etc). Pour identifier l’élément en particulier qu’il vise lorsqu’il définit une règle CSS, le développeur va utiliser un sélecteur CSS. Les sélecteurs CSS sont semblables à des « étiquettes » que l’on viendrait coller sur des dossiers afin de les différencier les uns des autres. Les sélecteurs principaux sont les classes et les Id. A partir de ces sélecteurs de base, beaucoup d’autres sélecteurs existent : ceux permettant de pointer sur les éléments voisins d’un premier élément précis, ceux permettant d’identifier un élément à partir d’un attribut, ceux définissant les règles au survol de la souris sur l’élément choisi…
Dans la majeure partie des cas, la personne qui construit un script de web scraping va, pour sélectionner les éléments qu’il vise et qui contiennent la donnée qu’il convoite, utiliser lui aussi ces fameux sélecteurs CSS. C’est la raison pour laquelle une bonne connaissance de ces sélecteurs et de la façon de les utiliser est indispensable lorsque l’on souhaite devenir performant dans le domaine du web scraping.
Pour ceux qui veulent en savoir plus, je vous conseille cet article qui, bien qu’il date de 2011, est toujours d’actualité, le domaine des sélecteurs CSS étant l’un des rares qui, dans le web, ne soit pas soumis à de constants changements.
8 - Proxy
Comme vous pourrez le voir dans le cadre de notre formation avancée au web scraping, différentes techniques doivent être trouvées pour contourner les systèmes de sécurité anti-scraping. En effet, il serait naïf de penser que les propriétaires de sites web étant fréquemment soumis à des scraping provenant de différents acteurs (typiquement, les sites d’immobilier, les sites d’annonces en tout genre, tout site permettant de récupérer de l’information ayant de la valeur et/ou des coordonnées permettant par la suite de prospecter) vont laisser n’importe qui venir se servir sans ne rien faire. Différentes techniques peuvent être utilisées afin de compliquer la tâche des web scraper. Nous consacrerons bientôt un article complet à ce thème.
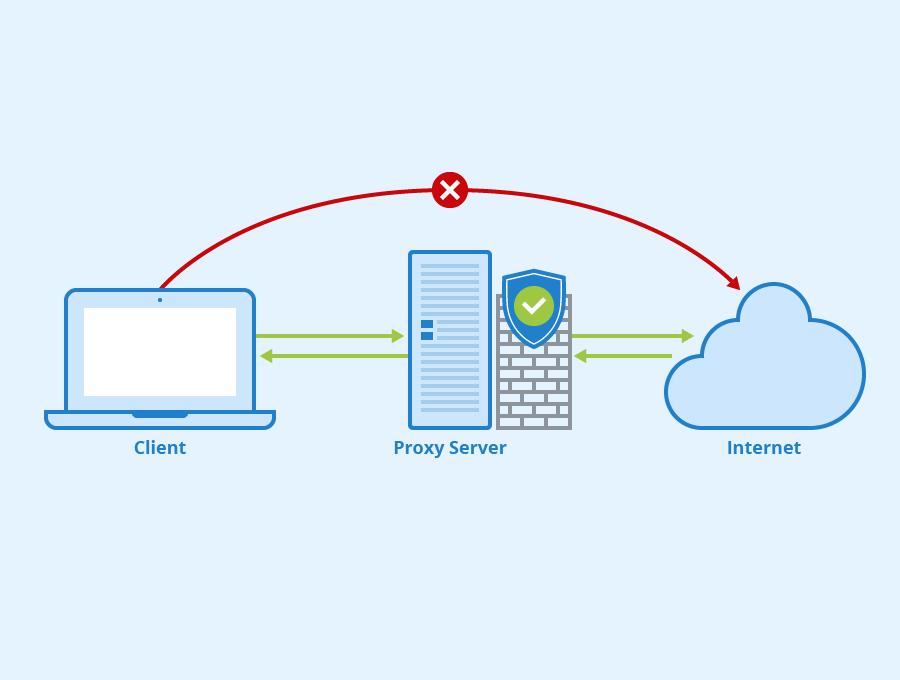
Parmi ces techniques, l’une des plus répandues consiste à surveiller l’activité du site. Côté serveur, on met en place des règles qui font que, si une même adresse IP se connecte de façon trop répétée et parcourt un trop grand nombre de pages sur un espace de temps limité, on en déduit qu’il s’agit d’un robot, et dans ce cas, on coupe l’accès au serveur hébergeant le site pour cette adresse IP (cette interdiction n’est que temporaire, mais cela suffit à casser le rythme de votre scraping). Pour y remédier, le web scraper expérimenté va se connecter au site en passant par un proxy. Le proxy est un serveur intermédiaire, que l’on utilise en tant que « masque ». Ce serveur dispose d’un accès internet et donc, d’une adresse IP.
Le principe est le suivant : nous nous connectons d’abord au proxy, qui récupère l’URL du site que l’on souhaite joindre, et se charge de nous mettre en relation avec lui, en faisant office d’intermédiaire. Ainsi, nous n’allons pas nous connecter au site final avec notre adresse IP, mais avec celle du proxy. Si l’on change de proxy a chaque nouvelle requête vers le site final (ou toute les 5 requêtes admettons), vous comprenez que la sécurité anti-scraping sera du coup beaucoup moins efficiente.
Vous souhaitez bénéficier d'une formation présentielle en web scraping ? Vous pouvez probablement vous faire financer une de nos formations ! Pour en savoir plus téléchargez le programme de nos formations physiques.