Le premier réflexe qui nous vient lorsque l’on cherche à se former à la récupération de données sur le web est de se focaliser sur les outils à utiliser. Qu’ils soient payants ou gratuits, ces outils sont nombreux. Cependant, si votre première approche vis-à-vis du web scraping consiste en cela, sachez que vous êtes en train de brûler les étapes. Nombreux sont ceux qui cherchent à comprendre comment récupérer de la donnée avant d’avoir compris comment celle-ci est générée. Il s’agit donc d’un fonctionnement en sens inverse de ce que le bon sens voudrait. Je vais donc vous présenter ici la méthodologie que je préconise. Cette méthodologie représente pour moi l’analyse préalable essentielle dans le cadre d’une opération de web scraping. A chaque fois que vous tomberez sur un site web affichant des données qui pourraient vous intéresser, cette méthode vous sera d’une grande utilité car elle vous permettra de comprendre comment elles sont générées, et ainsi, vous serez plus lucide sur la façon la plus appropriée de les récupérer.
 +336 67 57 33 79
+336 67 57 33 79
Web scraping: comment analyser correctement un site web afin d'aller y récupérer de la donnée ?
Les 3 différents types de site existants dans le cadre du web scraping
Avant toute chose, vous devez savoir qu’il existe, en termes de chargement de données, 3 types distincts de site web :
- Les sites web disposant d'une API
- Les sites web ne disposant pas d’API et chargeant leurs données côté serveur (back)
- Les sites web ne disposant pas d’API et chargeant leurs données côté navigateur (front)
Notre méthodologie a pour but de définir la catégorie à laquelle appartient le site web sur lequel on souhaite récupérer de la donnée.
Données provenant d’une API
La première question consiste à donc voir si ce site dispose d’une API. Pour cela, vous devez utiliser les outils de développement de votre navigateur. Je vous conseille d’utiliser Mozilla Firefox dans ce cadre, même si vous pouvez faire la même chose avec Google Chrome. Rendez-vous sur le site web en question, puis appuyez sur F12 afin d’activer l’affichage de la console de développement. Ici nous allons faire le test sur le site seloger.com.
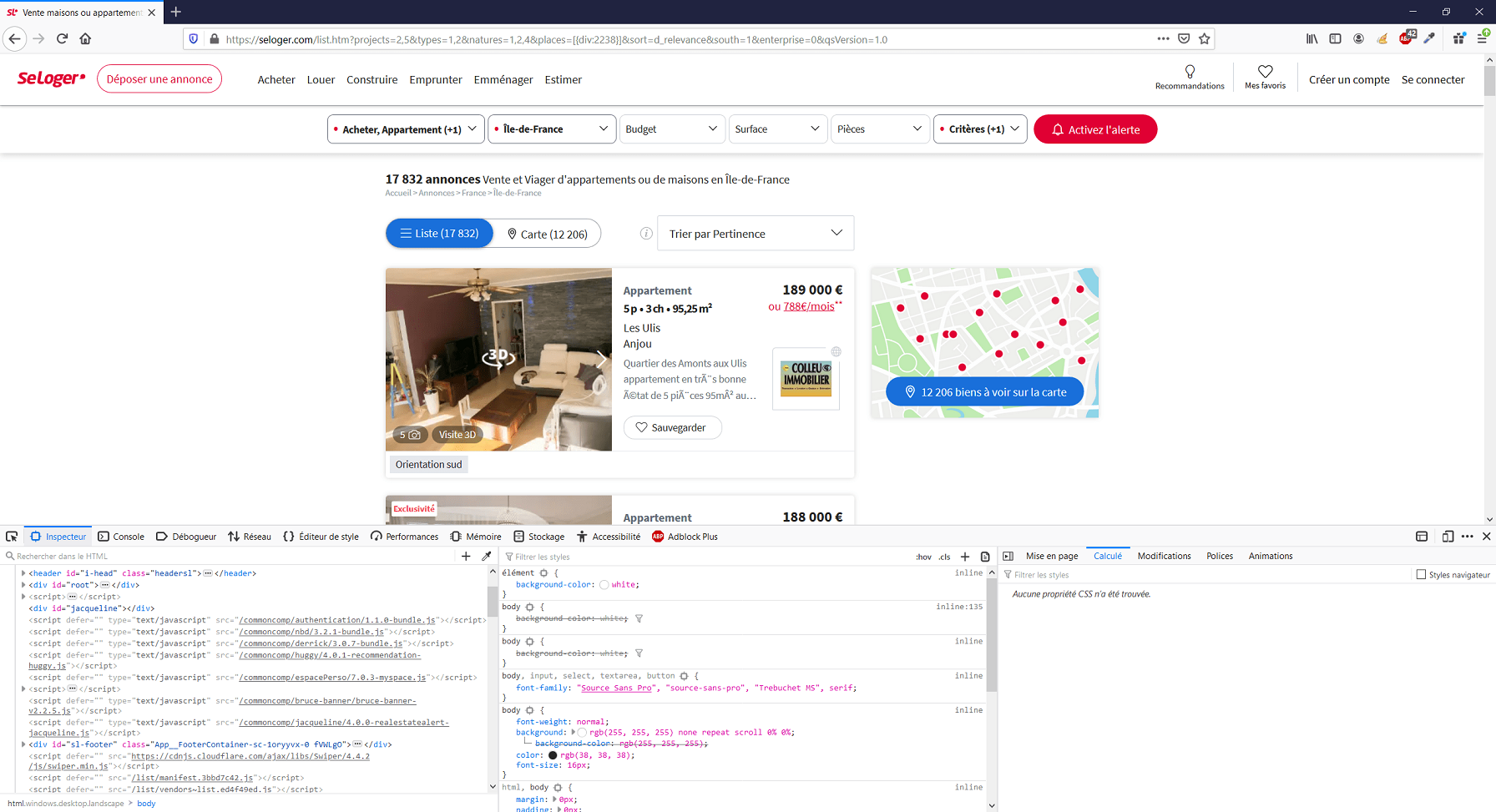
Dans la console, rendez-vous sur l’onglet « Réseau ». Ce menu vous donne des informations concernant toutes les ressources chargées par le site web via le navigateur (fichiers CSS et JavaScript, images, polices, etc.). Par défaut, la console affiche toutes ces ressources sans distinction. Nous allons filtrer en appuyant sur le bouton de filtre « XHR » (si rien ne s’affiche, c’est probablement que vous devez actualiser la page). Nous n’allons pas ici rentrer dans les détails concernant l’objet XHR, mais sachez simplement que c’est dans cette partie que nous retrouverons les appels effectués en direction d’une API, s’il y en a. A ce moment là, dans la liste d’appels que vous trouverez dans la partie principale de la console, il va falloir « mettre les mains dans le cambouis ». En effet, cette partie de l’analyse demande à ce que l’on fonctionne en fouillant, sans repère particulier. Commencez par cliquer sur le premier élément, puis, dans la partie de droite, donnant les infos relatives à l’appel que vous avez sélectionnez, placez vous sur l’onglet « Réponse ». Ainsi s’afficheront les données retournées par l’appel sélectionné. Il va donc falloir que vous fassiez défiler les différents appels, sur la partie gauche de la console, et que vous regardiez à chaque fois, dans la partie droite de la console (sous l’onglet « Réponse ») si vous voyez des infos relatives aux données que vous cherchez à récupérer. Oui, en effet, c’est une façon de fonctionner peu « méthodique » pour le coup, et nécessitant improvisation et débrouillardise, mais le web scraping n’est pas une science exacte ;).
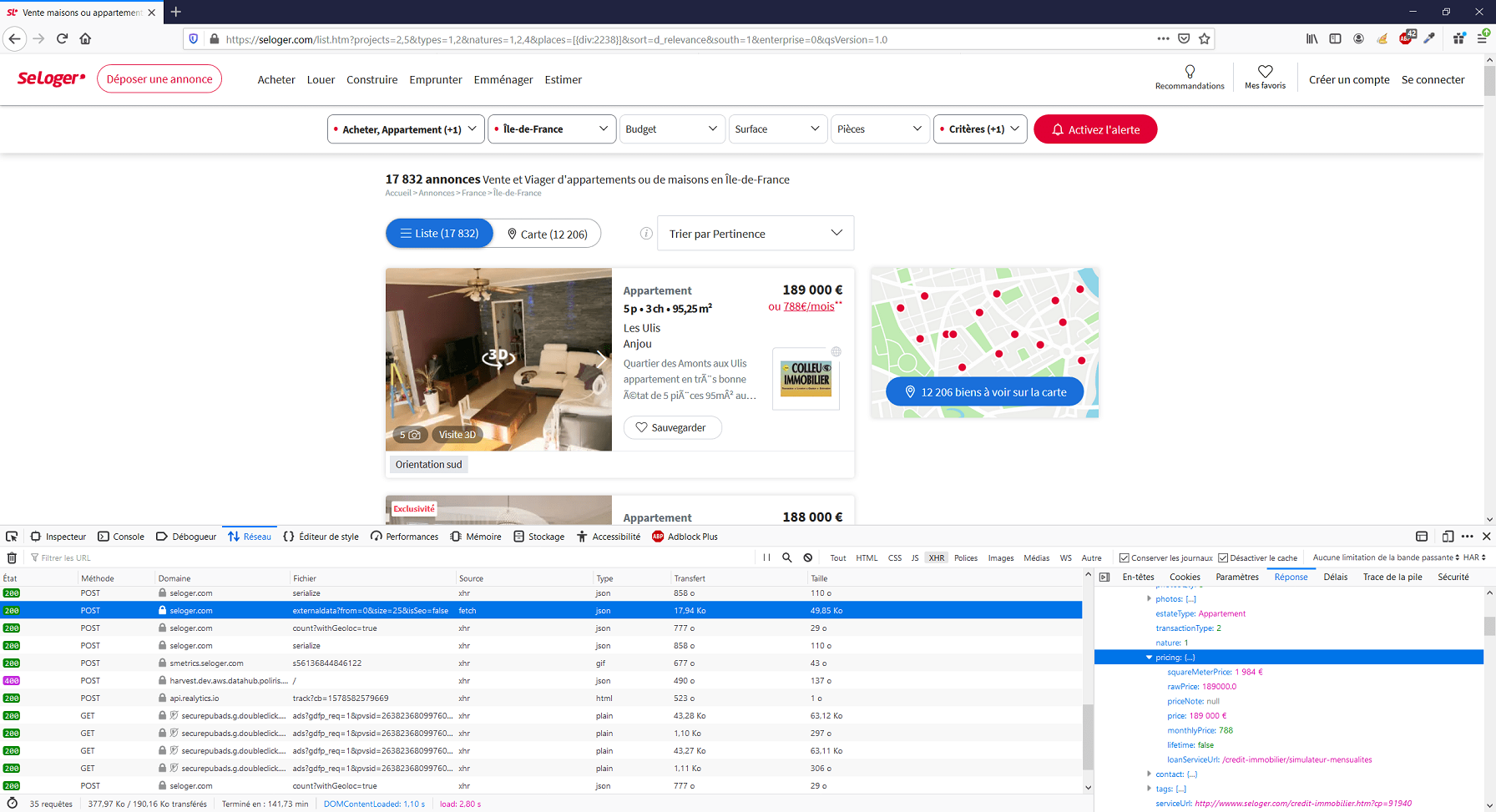
Dans l’image ci-dessus, vous voyez que l’on parvient à trouver ce que l’on cherchait. Dans la colonne de droite, nous voyons bien qu’un des appels effectués renvoi une liste d’infos relatives à chacune des annonces de logement affichées sur la page. Une fois que vous avez mis le doigt sur cet appel, cliquez désormais, dans la colonne de droite, sur l’onglet « En-têtes ». La première info que vous verrez ici est l’URL de la requête.
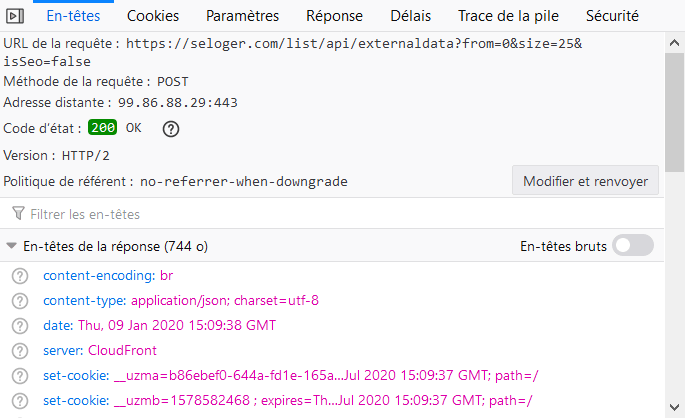
A partir de là, vous disposez donc de l’URL de l’API vers laquelle le site effectue ses appels afin de charger la donnée que vous voyez affichée sur la page.
Le diagnostic s’arrête là dans un premier temps. Vous savez désormais que le site sur lequel vous êtes appartient à la première des 3 catégories que nous avons listées.
Donnée générée côté navigateur ou côté serveur ?
Dans le cas où vous ne trouveriez pas de trace d’une API après être passé par l’étape précédente, cela signifie qu’il va falloir savoir à laquelle des 2 catégories restantes appartient le site web. Ne vous inquiétez pas, le plus dur est derrière vous ! Ici, il y a une façon très simple de distinguer les sites chargeant leurs données côté serveur de ceux qui la chargent côté navigateur.
Le principe est simple : sur le site que vous analysez, vous allez consulter le code source, et, si les informations qui vous intéressent s’y trouvent, cela veut dire que ces données n’ont pas eu besoin d’être générées par le navigateur, mais étaient déjà présentes dans le code initial reçu par celui-ci. Elles ont donc été générées côté serveur.
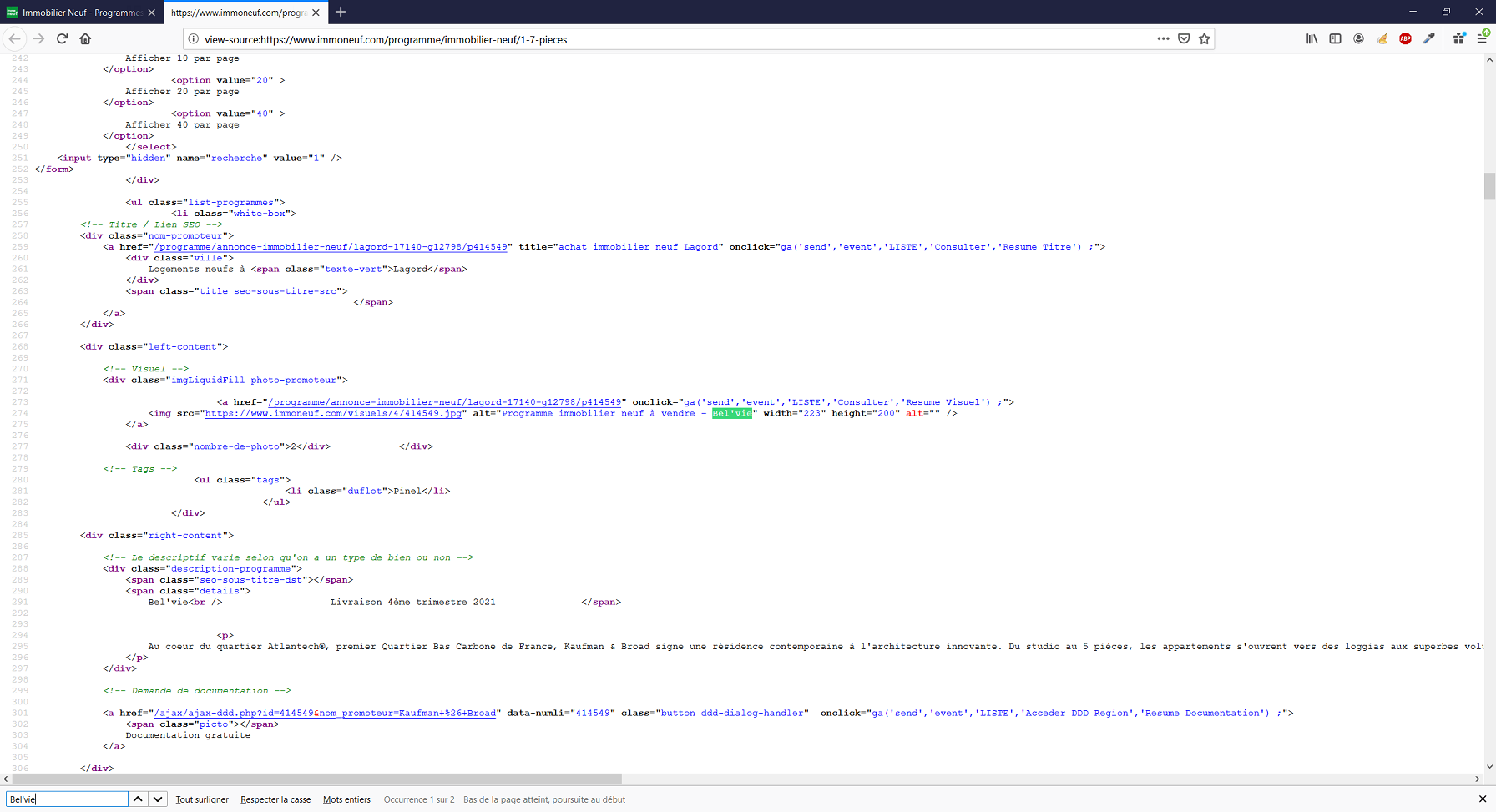
Nous prenons ici pour exemple le site immoneuf.com. Faites un click droit et choisissez l’option vous permettant d’afficher le code source de la page.
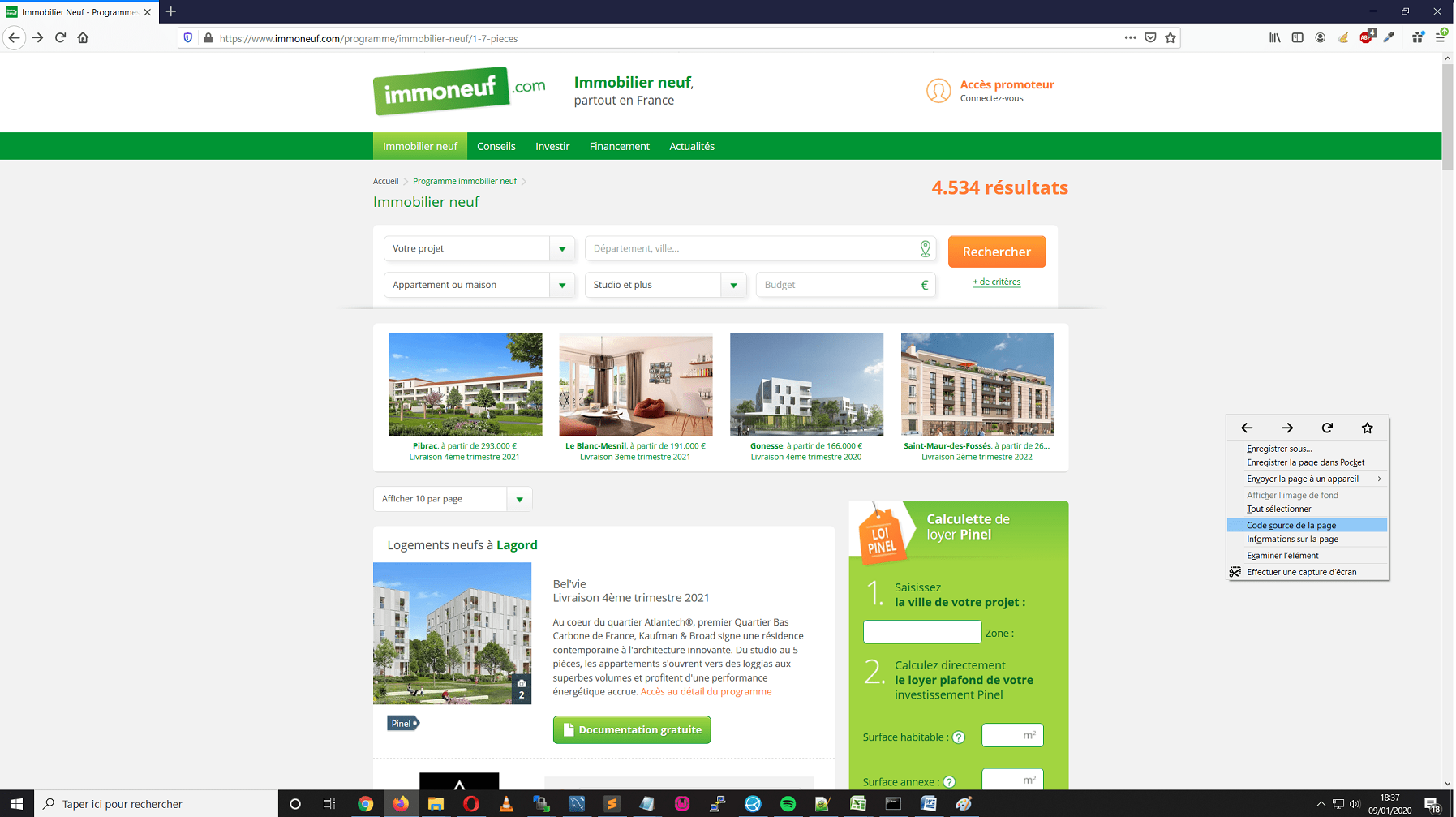
Dans le nouvel onglet contenant ce fameux code source, faites désormais une recherche textuelle sur une des informations vous intéressant. Ainsi vous pourrez savoir si les données qui vous intéressent son générées côté navigateur ou serveur en fonction de cette observation.
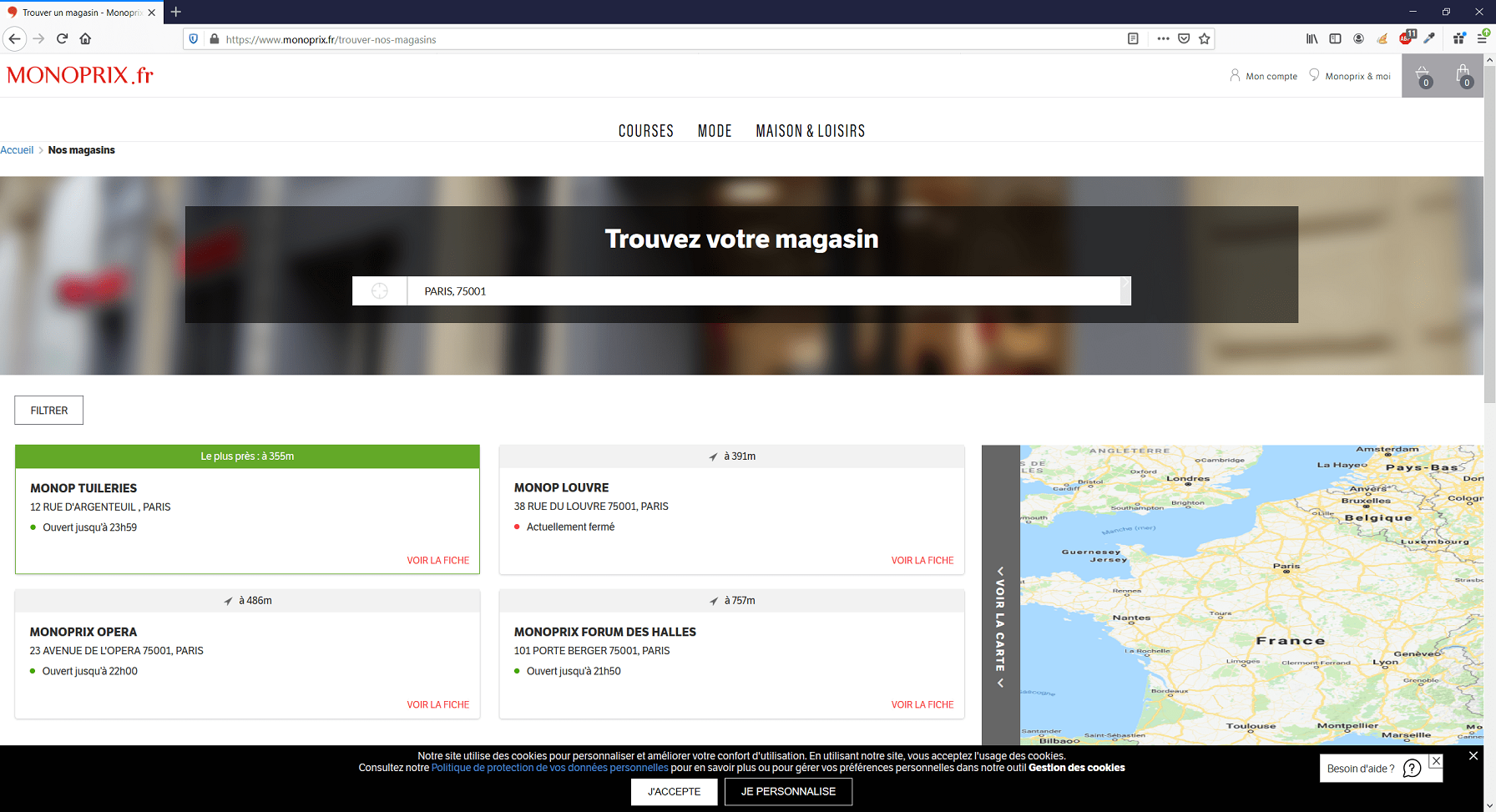
Je prends un second exemple avec le site monoprix.fr. Et ici, on constate que le code source contient peu de lignes. Il s’agit d’un site générant une grande partie des infos affichées coté navigateur.
Fin du diagnostic et pistes à envisager
Vous êtes donc désormais en mesure de pouvoir classifier le site que vous avez analysé. Quel est l’intérêt de savoir à quel « type » appartient ce site ? Cette information est capitale pour la bonne et simple raison qu’en fonction de ce « type », les moyens qui devront être mis en œuvre pour effectuer le scraping le plus approprié seront différents.
- Les sites web disposant d’une API: Si l’API n’est pas soumise à un système de sécurité : possibilité de récupérer de la donnée (dans une certaine mesure) sans avoir à coder, via le navigateur, via le logiciel Postman, via des outils en ligne simples d’utilisation…
- Les sites web ne disposant pas d’API et chargeant leurs données côté serveur (back): possibilité de récupérer de la donnée sans avoir à coder via l’extension Google Chrome « Web Scraper » dans certains cas et dans une certaine mesure, pour le reste le développement devra se faire via des librairies de scraping classiques.
Exemples : Cheerio.js, PHP Simple HTML DOM Parser, BeautifulSoup… - Les sites web ne disposant pas d’API et chargeant leurs données côté navigateur (front): possibilité de récupérer de la donnée sans avoir à coder via l’extension Google Chrome « Web Scraper » dans certains cas et dans une certaine mesure, pour le reste le développement devra se faire via l’utilisation de librairie de scraping en headless-browser (plus spécifique et moins nombreuses que les librairies dites « classiques »).
Exemples : Puppeteer, Selenium…
Si vous avez des compétences en développement web ou que vous maitrisez un outil de web scraping sans code tel que l’extension Web Scraper, ce diagnostic vous permet donc de savoir comment opérer. Dans le cas où vous avez l’habitude de faire appel à des prestataires pour effectuer vos missions de web scraping, le fait de pouvoir effectuer cette analyse vous permet une meilleure compréhension du travail que ceux-ci devront effectuer, ce qui vous permettra d’être moins dépendant de leurs explications dans le cadre de vos échanges.
Vous souhaitez bénéficier d'une formation présentielle ? Vous pouvez probablement vous faire financer une de nos formations ! Pour en savoir plus téléchargez le programme de nos formations physiques.