N’importe quelle personne s’intéressant à la thématique du web scraping pourra constater, après un rapide tour sur le web, que le langage traditionnellement associé à cette pratique est Python. Que ce soit dans le but de trouver de la documentation écrite, ou des tutos vidéos, le résultat est le même. Comment expliquer cela ? Le Python est il un langage indispensable pour toute personne souhaitant faire du web scraping ? Ce lien automatique entre web scraping et Python est il justifié ?
Pour être plus précis, à la suite de quelques recherches sur le web, vous comprendrez rapidement que la pratique du web scraping se répartie majoritairement, et globalement, à travers 3 langages distincts : Python, Node et R.
Dans les faits, on peut faire du scraping avec n’importe quel langage web. A travers ma formation avancée au web scraping, nous vous avons d’ailleurs montré comment faire du web scraping en PHP. Cependant, certains langages disposent de librairies plus ou moins dédiées, et plus ou moins performantes, dans le domaine du scraping.
Nous allons ici nous concentrer sur la comparaison entre Python et Node, qui sont actuellement les 2 langages les plus réputés dans ce domaine.
Afin de vous introduire au sujet avant de passer à la lecture, vous pouvez consulter notre infographie.
 +336 67 57 33 79
+336 67 57 33 79
Web scraping en Python ou en Node ? Quel langage choisir ?

1 – Qui a les meilleures librairies ?
Voici en effet le premier critère à partir duquel nous pouvons effectuer une comparaison. La qualité des librairies proposées est un sujet central. Et c’est, à mon avis, l’une des principales raisons nous permettant d’expliquer la réputation dont dispose traditionnellement Python à ce sujet. En effet, le langage a été un des premiers à proposer des librairies dédiées au scraping. A titre d’exemple, la librairie Beautiful Soup existe depuis 2004. A cette date, Node n’existe même pas (la première version sortira en 2009). Cette dimension de « pionnier » joue sans doute beaucoup dans l’image que l’on a encore aujourd’hui de Python et de son rapport au web scraping. Pourtant, si on en juge à la qualité objective des librairies, il ne semble pas il y avoir de raisons particulières de donner l’avantage à Python. Pour ce qui est du scraping à destination des sites « statiques » (rendu serveur), la librairie Beautiful Soup est en effet un outil très maniable et performant. En Node, la librairie Cheerio est tout autant efficace. Si vous maitrisez la syntaxe jQuery, l’utilisation de Cheerio vous sera particulièrement intuitive. Si l’on exclut la sensibilité personnelle et les goûts de chacun, il est difficile d’accorder une supériorité à l’un de ces deux outils. En ce qui concerne les librairies permettant de détecter le contenu dynamique via un headless browser, il semblerait en revanche qu’un léger avantage puisse être accordé à Node. De façon logique, JavaScript étant à l’origine un langage front, il est plus naturel de piocher dans le DOM d’une page web en utilisant ce langage plutôt qu’en passant par Python. De plus, les temps d’exécution sont plus rapides avec Puppeteer qu’avec Selenium (les deux principales librairies utilisant du headless-brower respectivement sous Node et Python). Ajoutons par ailleurs que, compte tenu de l’activité frénétique émanant de l’univers Js, et la quantité de paquets publiés chaque jour sur NPM, les outils de web scraping disponibles en Node sont plus nombreux qu’en Python.
2 – Quel langage est le mieux adapté à la pratique du web scraping ?
Il s’agit ici d’une question assez vague. Si je la pose, c’est qu’il m’arrive souvent d’entendre des propos de ce genre. En réalité, Python est un langage qui est assez répandu dans le domaine scientifique, et tous ceux nécessitant des opérations mathématiques complexes (intelligence artificielle, deep learning, cartographie…). Python n’est pas réputé pour être un langage particulièrement performant en rapidité de calcul, comparativement à des langages comme Java ou C++. Cependant, il dispose de nombreuses librairies dédiées à ces domaines. De plus, la technologie Cython permet justement de créer un pont entre Python et le langage C/C++. Par son biais, plusieurs librairies utilisées sous Python sont en fait basées sur du code en C/C++. Ce qui permet donc d’allier la puissance du C, à la flexibilité et la simplicité de prise en main attribuable au langage Python. Ainsi, dans la continuité de ce que l’on vient de voir ici, il est logique que le Python bénéficie également d’une bonne réputation dans le domaine du Data mining, où des opérations et traitements complexes sont effectués. Cependant, nous nous trouvons ici à l’étape suivant celle qui nous intéresse : la collecte de données. Pour ce qui est du web scraping, rien ne nous permet, au niveau de la syntaxe même ou de la puissance de calcul du langage, d’affirmer que Python est supérieur à Node.
3 – Gestion des requêtes simultanées
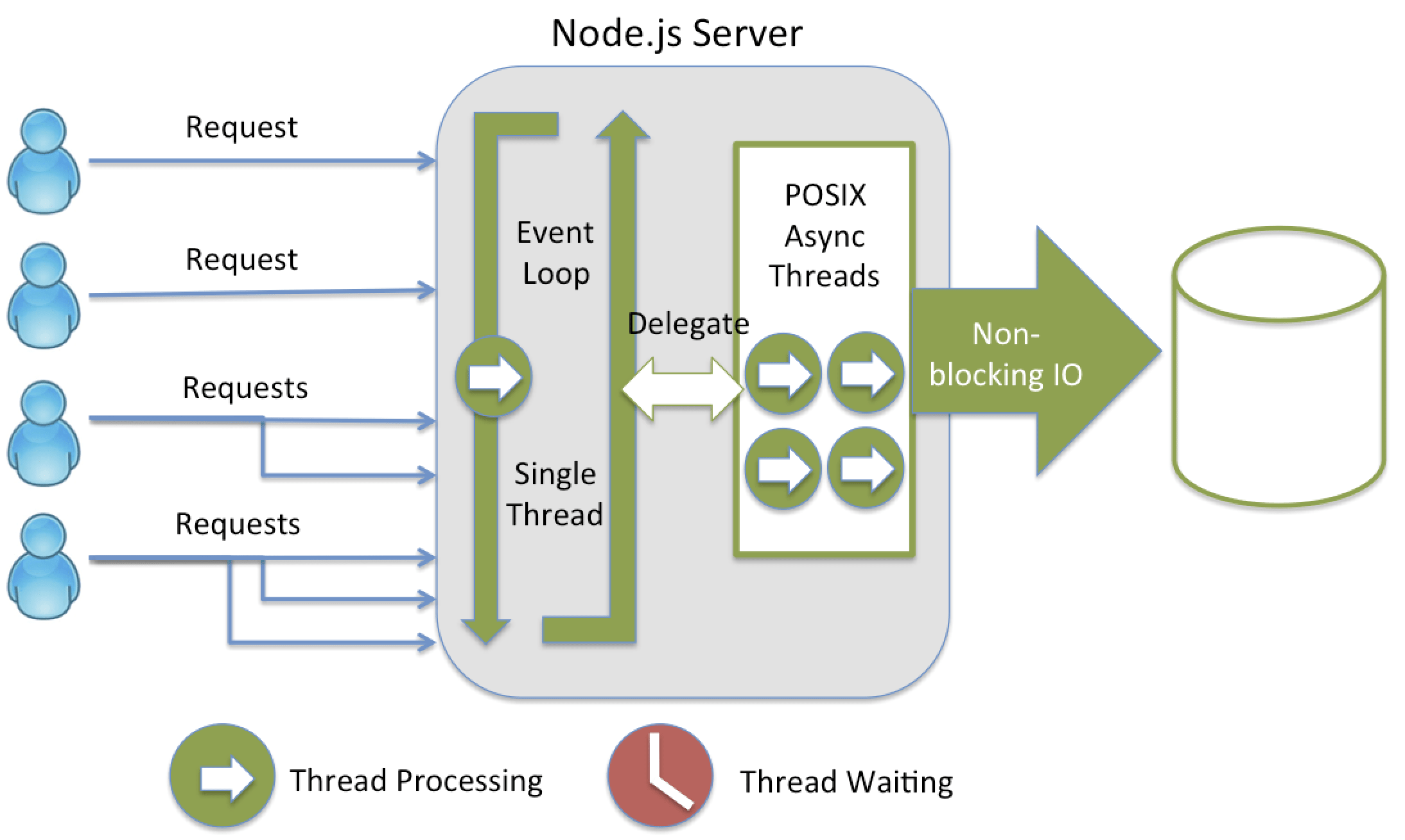
Un autre sujet important est celui de la capacité à gérer un nombre important de requêtes de façon simultanée ou, dirons nous, parallèle. Vous avez probablement eu des échos de la part de développeurs Node quant au fameux sujet des callbacks imbriquées (on parle ici du fameux « callback hell »), pouvant rendre le code indigeste si une certaine discipline n’est pas respectée. Derrière cet aspect pouvant à priori repousser les plus frileux se cache en fait l’une des forces de Node : la capacité à exécuter facilement du code asynchrone.
En gros, là ou en Python le code est exécuté ligne par ligne, de façon séquentielle et hiérarchisée, sous Node, le code est interprété en mode « non-bloquant ». A titre d’exemple, vous appelez une fonction au sein d’un script. En Python, la fonction est appelée, et tant que le travail effectué par cette dernière n’est pas terminé, on ne passe pas à la ligne suivante dans le script d’origine. En Node, par défaut, c’est l’inverse. Si vous souhaitez que la fonction ait terminé son travail avant de passer à la ligne suivante du script, ce sera à vous de structurer votre code d’une certaine façon afin de le faire comprendre au serveur Node (c’est justement dans ce cadre qu’interviennent les callbacks et autres mots clés comme async/await). Cette particularité du langage JavaScript le rend particulièrement utile lorsque l’on souhaite effectuer plusieurs tâches de façon simultanée ou parallèle. Ainsi, dans le cadre du web scraping, cela représente clairement un intérêt, car il vous est possible de lancer votre robot sur plusieurs pages en même temps, plutôt que de devoir attendre la fin du scraping de la première page pour pouvoir passer à la seconde.
Si vous souhaitez faire de l’asynchrone en Python, cela est possible, en passant par exemple par la libraire Asyncio. Cependant, cela n’étant pas le fonctionnement natif du langage, la pratique de l’asynchrone apparait comme étant plus facile et performante sous Node. Sur ce point, nous pouvons donc donner l’avantage à Node.
4 – Comment faire son choix ?

Au final, le but est de vous faire comprendre que, comme c’est souvent le cas lorsqu’il s’agit de réputation, celle de Python au sujet du web scraping est en partie basée sur des éléments datés, ou ayant évolués. Python reste un excellent langage pour faire du scraping, mais il serait faux d’estimer que cela est moins le cas pour Node.
En réalité, votre choix doit se faire de façon stratégique, en se basant sur une vision plus large. Je vous fais part ici de mon point de vue quant au choix que vous devez faire:
- Au-delà de la collecte de données, vous souhaitez (ou vous envisagez, à l’avenir) développer vos compétences en termes de data mining, de deep learning, d’intelligence artificielle…
- La syntaxe JavaScript vous insupporte et vous êtes soucieux de produire un code propre et clair
Choisissez Python !
- Au-delà de la collecte de données, vous aimeriez avoir des compétences vous permettant d’agir coté front, et vous n’avez pas le temps (ou ne voyez pas l’intérêt) d’apprendre 2 langages différents (1 pour le back, 1 pour le front).
- Vous portez peu d’attention à la syntaxe ou à la rigueur du langage, votre priorité est l’adaptabilité et le fait de pouvoir intervenir sur un nombre particulièrement large de projets/produits/interfaces web différents.
Choisissez Node !
Pour plus d'informations, consultez notre infographie à ce sujet !
Vous souhaitez bénéficier d'une formation présentielle en web scraping ? Vous pouvez probablement vous faire financer une de nos formations ! Pour en savoir plus téléchargez le programme de nos formations physiques.