Si vous vous intéressez au web scraping mais que vous n’êtes pas un professionnel du web, la documentation que vous allez être amené à consulter (y compris celle que vous trouverez ici) risque d’être parsemé de mots, termes ou concepts assez obscurs pour vos yeux de néophyte. Pas d’inquiétude, plutôt que de rire de votre sort du haut de mon siège de développeur, je vais essayer de vous transmette un petit lexique qui, je l’espère, vous sera d’une grande aide.
 +336 67 57 33 79
+336 67 57 33 79
23
jan
Les 8 concepts clés que vous devez maitriser si vous débutez dans le web scraping (Partie 1)
1 - Requête/Appel
Toute personne souhaitant récupérer de la donnée sur le web sera amenée, à un moment ou un autre, à analyser les requêtes émises par le site qu’elle vise. En tant que simple internaute, vous émettez vous-même chaque jour des requêtes, en tapant une URL dans votre navigateur web. Il s’agit dans ce cas d’une requête de type HTTP. Le principe est simple : vous demandez à votre navigateur web qu’il aille récupérer le texte, les images, les fichiers…bref, le contenu du site dont vous avez indiqué l’URL, afin qu’il vous l’affiche et que vous puissiez interagir avec. Vous comprenez donc que le terme de « requête » correspond bien à la définition que nous en avons dans le langage courant : il y a un demandeur, et un récepteur, qui choisit de répondre ou non à la requête qu’il reçoit (dans le cas d’une URL erronée, vous allez recevoir une erreur 404 vous indiquant que le site ou la page demandée n’existe pas). Des requêtes, il y en a de différents types. Ce qui nous intéresse ici, ce sont celles que vous allez être amenées à rencontrer dans le cadre du web scraping. Dans notre article « Web scraping : comment analyser correctement un site web afin d’aller y récupérer de la donnée ? », la méthodologie que nous présentons est en partie basée sur l’analyse de certaines requêtes émises par le navigateur. Il s’agit plus précisément des requêtes de type AJAX.
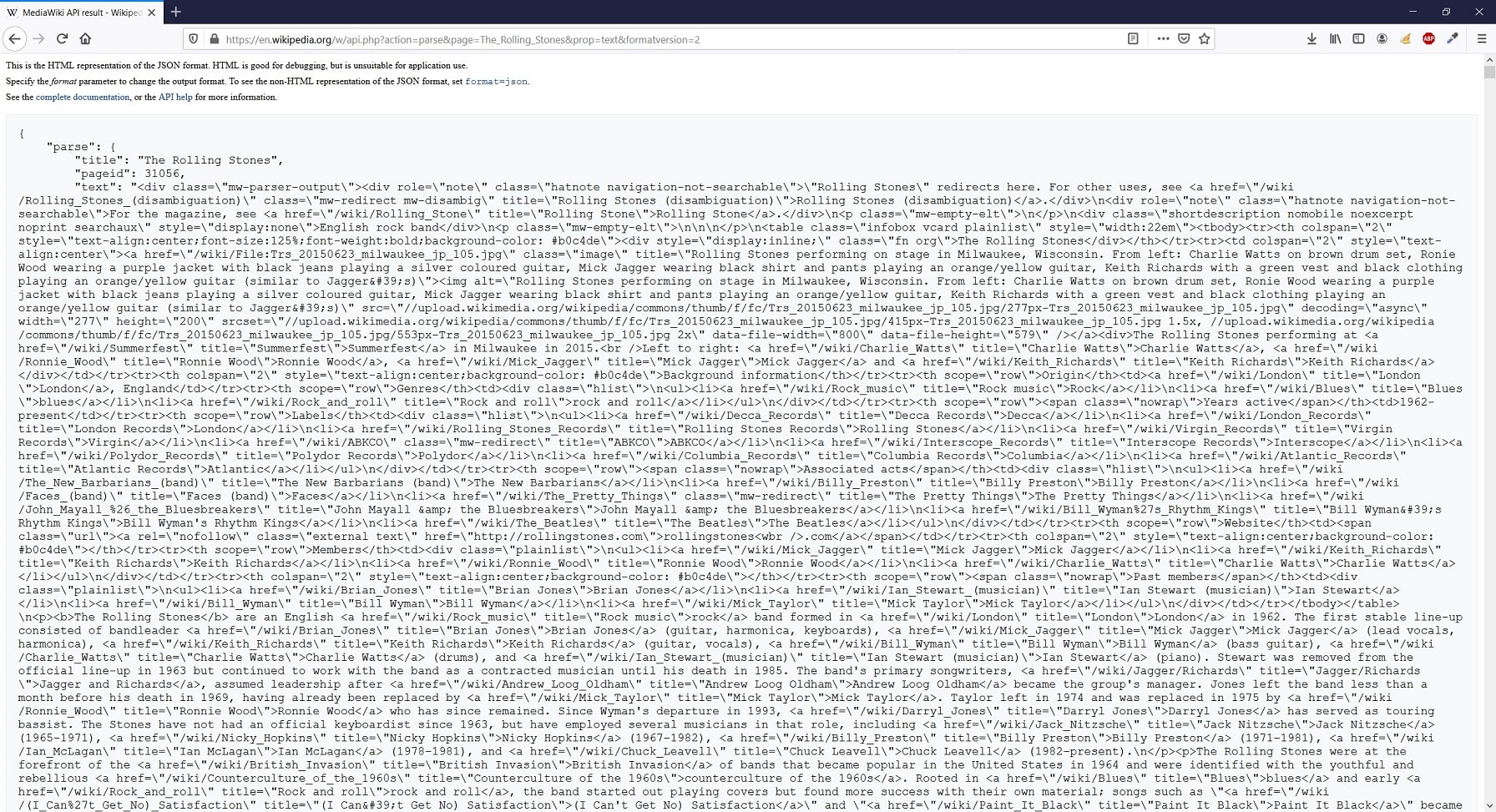
Comme nous l’expliquons dans l’article, à travers l’analyse de ces requêtes (on parle également d’ « appel »), nous cherchons à savoir si le contenu du site est récupéré à la suite d’une requête émise en direction d’une API. Si c’est le cas, cela pourrait éventuellement nous permettre d’aller récupérer la donnée souhaitée en émettant nous même une requête vers cette API (ce qui, dans le cadre d’une activité de web scraping, nous ferait gagner beaucoup de temps et faciliterait notre travail, car plutôt que de parcourir du code HTML afin d’en extraire ce qui nous intéresse, on irait nous servir directement à « la source »). Dans ce cadre, deux types de requêtes peuvent être utilisés : les requêtes en GET ou en POST. Il s’agit en fait de deux « sous-types » de requêtes HTTP (on parle ici de « méthodes HTTP »). Ces requêtes sont basées sur 2 informations essentielles : l’adresse identifiant l’API à laquelle on s’adresse, et les paramètres, permettant de spécifier l’objet de notre demande. Les requêtes en GET sont les plus « basiques » : elles tiennent dans une simple URL. Une API ouverte aux requêtes GET peut donc être testée via un simple navigateur web, en tapant l’URL dans la barre d’adresse. Les paramètres spécifiant notre demande sont directement insérés dans l’URL (ce sont toutes les informations se trouvant après le caractère « ? »).

Dans l’image ci-dessous, nous avons l’illustration d’une requête GET classique, effectuée via un navigateur. La partie se trouvant avant le « ? » est l’adresse de base de l’API (il s’agit ici de l’API officielle de Wikipédia), et celle après contient les différents paramètres, séparés par un « & ». On demande ici le contenu HTML de l’article Wikipédia ayant pour titre « The Rolling Stones ». Les requêtes POST sont plus complexes car les paramètres spécifiant notre demande ne peuvent être indiqués dans l’URL. Cela permet une plus grande sécurisation de l’échange. La méthode POST est celle utilisée dans le cadre d’envoi de formulaire sur un site web. Pour tester une API ne répondant qu’aux requêtes de type POST, vous devrez utiliser un logiciel comme Postman, votre navigateur ne suffira pas.
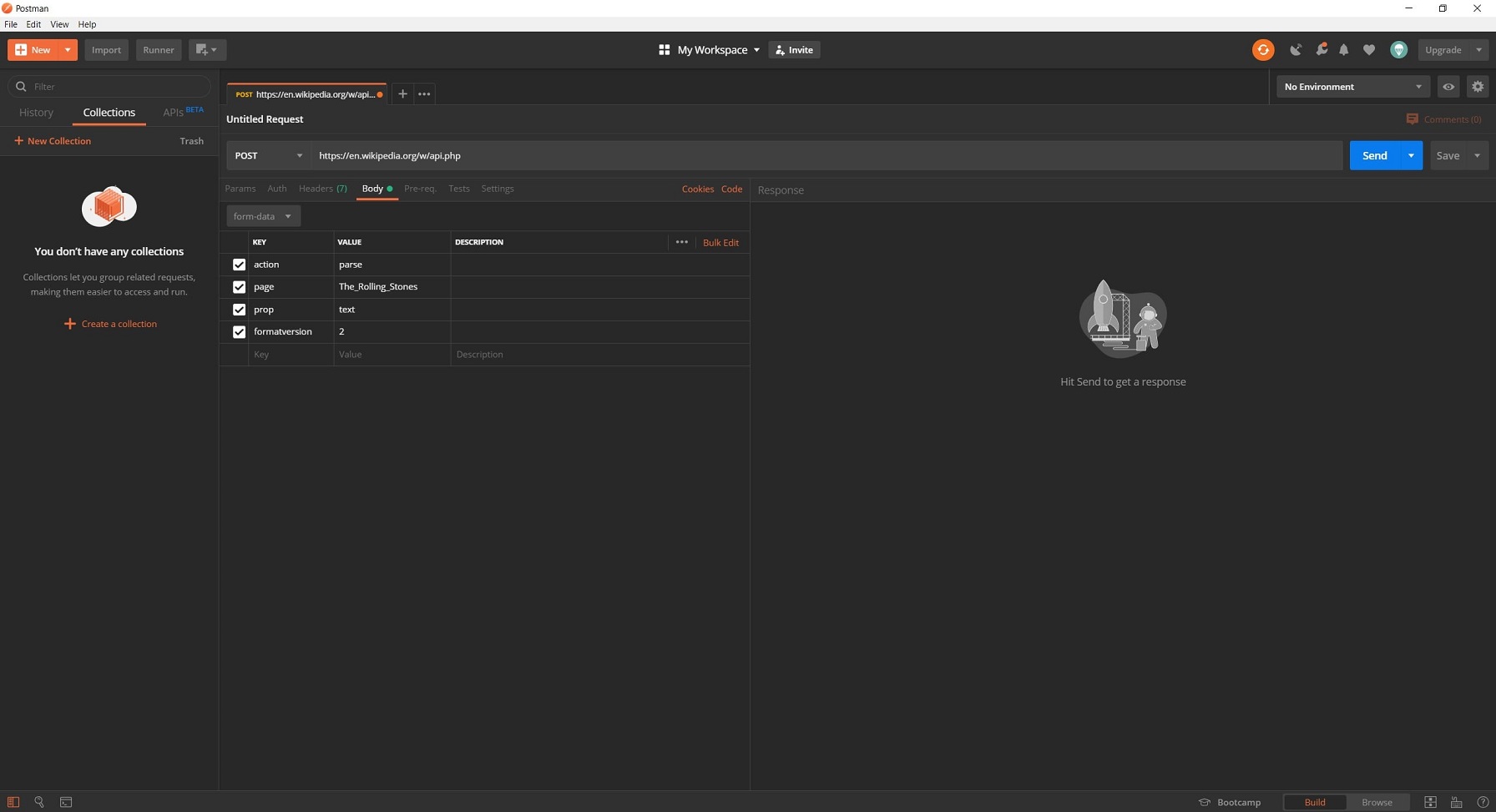
Ici vous avez l’illustration de comment il faudrait faire pour tester la requête GET précédente, dans le cas où elle devrait être effectuée via la méthode POST.
2 - Appel AJAX
Dans la continuité de ce que l’on vient d’expliquer, lorsque l’on soumet un formulaire de recherche sur un site web (prenons par exemple celui de la Fnac), une requête est envoyée vers la base de données pour voir s’il existe un produit correspondant au mot que vous avez tapé. Dans un web fonctionnant de façon « old school », la recherche va être effectuée en base de données, les produits correspondant vont être identifiés, et, côté navigateur (on parle donc ici de ce qu’il se passe sur votre écran), une nouvelle page contenant les résultats va être chargée. La technologie AJAX est ce qui permet de récupérer ces résultats sans avoir à recharger la page ou charger une nouvelle page. L’affichage s’effectue de façon « dynamique ». Dans le cadre du web scraping, le travail d’analyse que nous avons rappelé dans le point précédent se base en partie sur l’observation des appels AJAX observables sur le site. De nos jours, l’utilisation d’AJAX est très répandue sur le web. Si un site web récupère de la donnée via une API, il y a de grandes chances que vous trouviez des traces d’appels AJAX dans les outils de développement de votre navigateur (pour savoir comment s’y prendre, je vous invite de nouveau à consulter l’article détaillant cette méthodologie analytique). En tant que scraper, la différence est pour nous la suivante :
Méthode « old-school » : le navigateur transmet notre demande vers un fichier se trouvant sur le serveur. Le travail de ce fichier consiste à interroger la base de données, récupérer les résultats, et générer une nouvelle page contenant ces résultats. Tout se passe donc côté serveur.
Méthode AJAX : le navigateur transmet notre demande vers un fichier se trouvant sur le serveur. Ce fichier va interroger la base de données, récupérer les résultats et les renvoyer directement (généralement au format JSON) vers le navigateur.
Dans le premier cas, en tant qu’internaute lambda armé uniquement de notre navigateur web, nous n’avons aucune trace des informations transmises. Dans le second, nous en avons une (exemple ci-dessous).
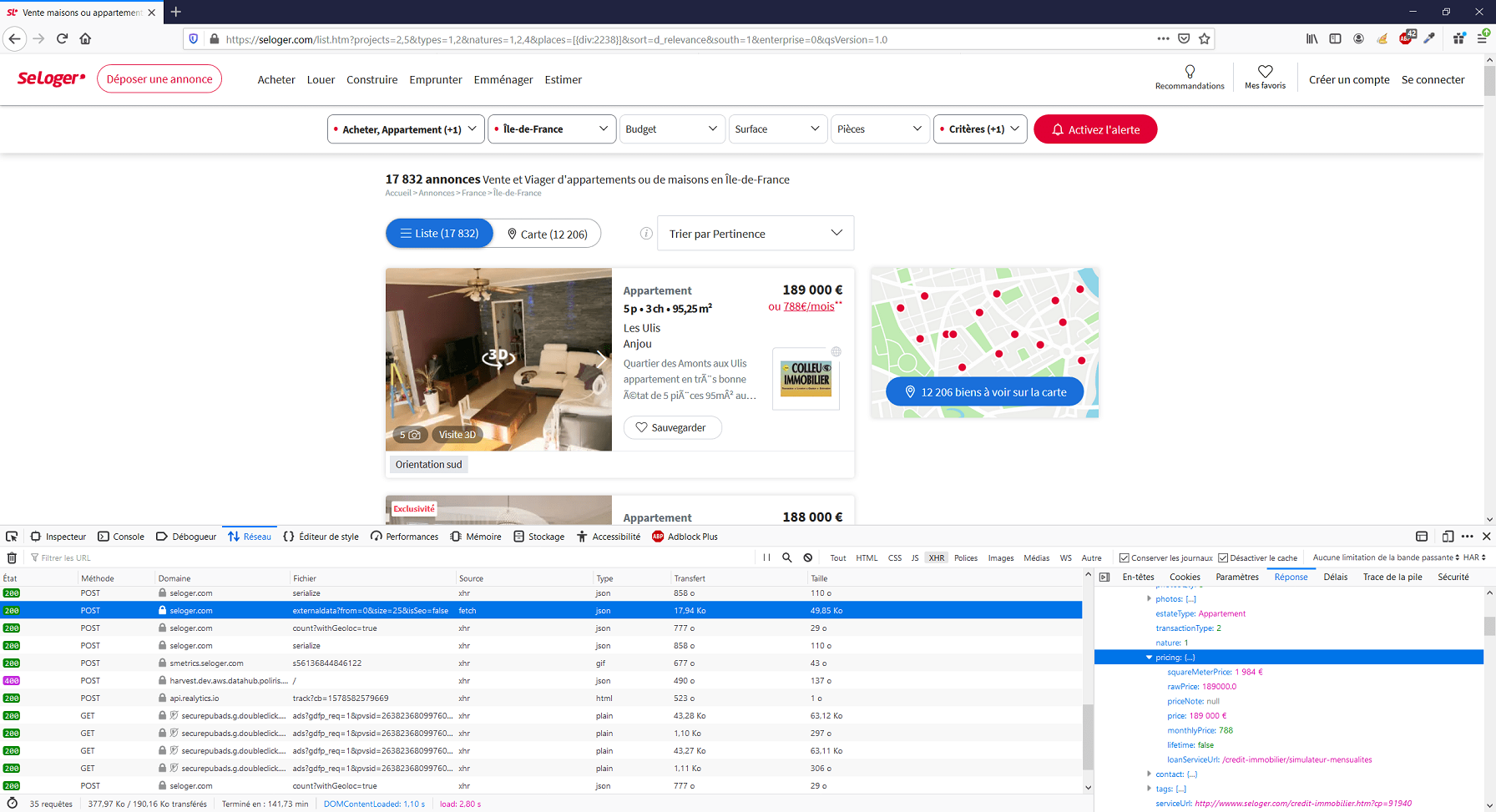
3 - JSON
Le JSON est un format de données. Ce format est très utilisé dans le domaine du web, et en particulier dans le cadre de la communication avec une API. Il s’agit d’un format léger, permettant de transférer rapidement et facilement des informations textuelles.

Ci-dessus un exemple illustrant la syntaxe JSON.
4 - API
Lorsqu’un développeur construit un site web, il s’agit pour lui d’afficher du contenu (texte, images, fichiers téléchargeables…), d’activer des fonctionnalités (envoi de mail via un formulaire, inscription à une newsletter…), et de structurer et mettre en forme tout cela de façon ergonomique pour que la navigation soit pratique et agréable pour l’utilisateur.
Lorsqu’un développeur construit une API, le but recherché est simplement de rendre facilement et rapidement disponible de la donnée. Ici, pas de mise en forme, pas de design, rien de tout cela, une API n’a pas vocation à être visitée et parcouru comme on le fait sur un site web. Il s’agit d’une interface qui a simplement pour mission de répondre à nos demandes en nous livrant de l’information.
Ainsi, de la même façon qu’un site web est généralement structuré en pages distinctes, l’API est elle structurée en « endpoints » (il existe différentes architectures possibles lorsque l’on conçoit une API, nous allons ici simplifier et nous baser sur ce que vous serez amené à rencontrer le plus souvent).
Sur le site web Wikipédia, si l’on souhaite consulter l’article présentant Léonard de Vinci, nous allons nous rendre sur l’URL suivante.

Ce qui va entrainer l’affichage, sur notre navigateur web, de l’article en question, mis en forme, tel que l’on a l’habitude de le voir.
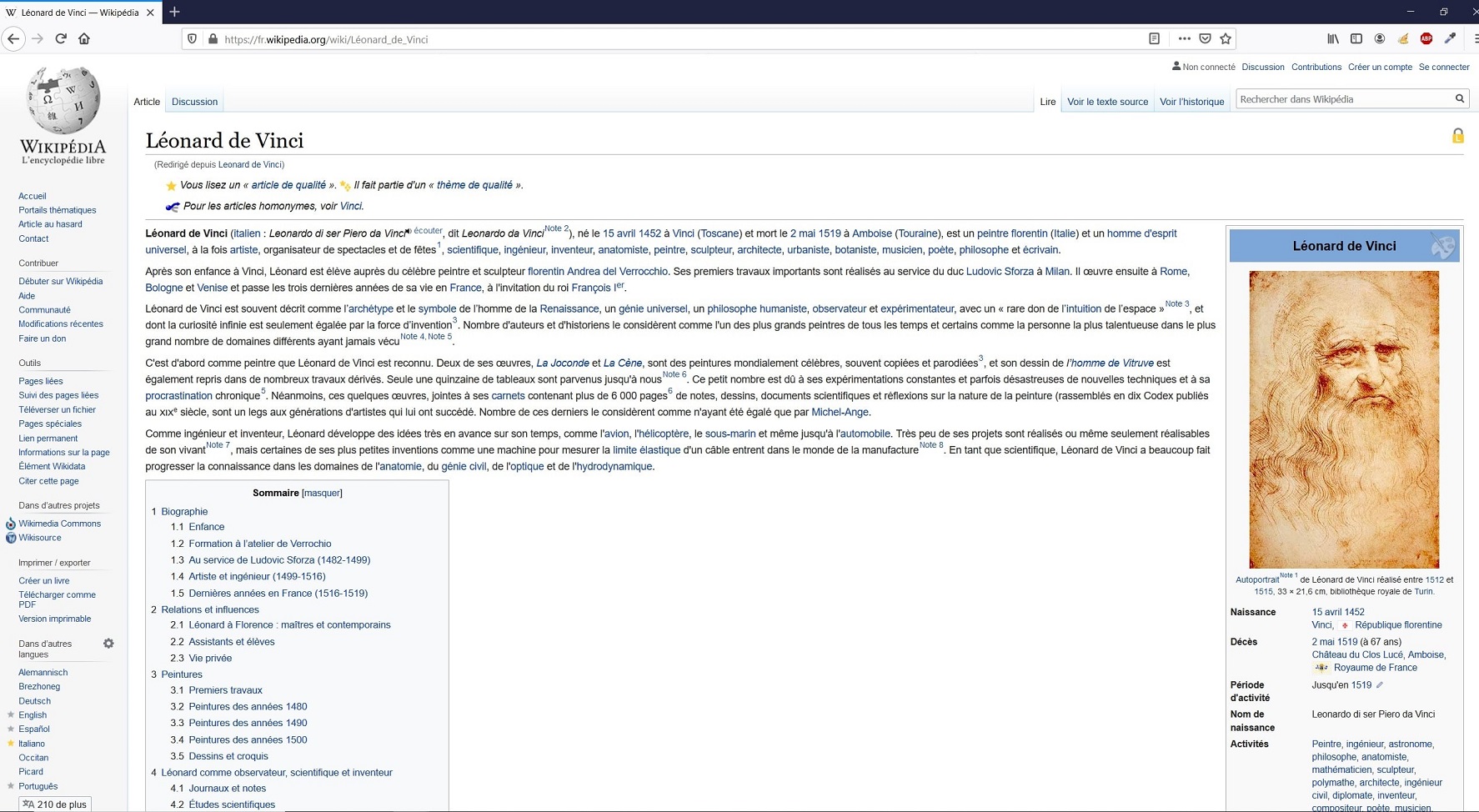
Mais comme nous l’avons vu précédemment, Wikipédia dispose aussi d’une API. Le « endpoint » nous permettant d’accéder aux informations que l’on voit affichées sur l’article ci-dessus est le suivant :

En tapant cette URL dans notre navigateur, voila ce qui s’affiche :
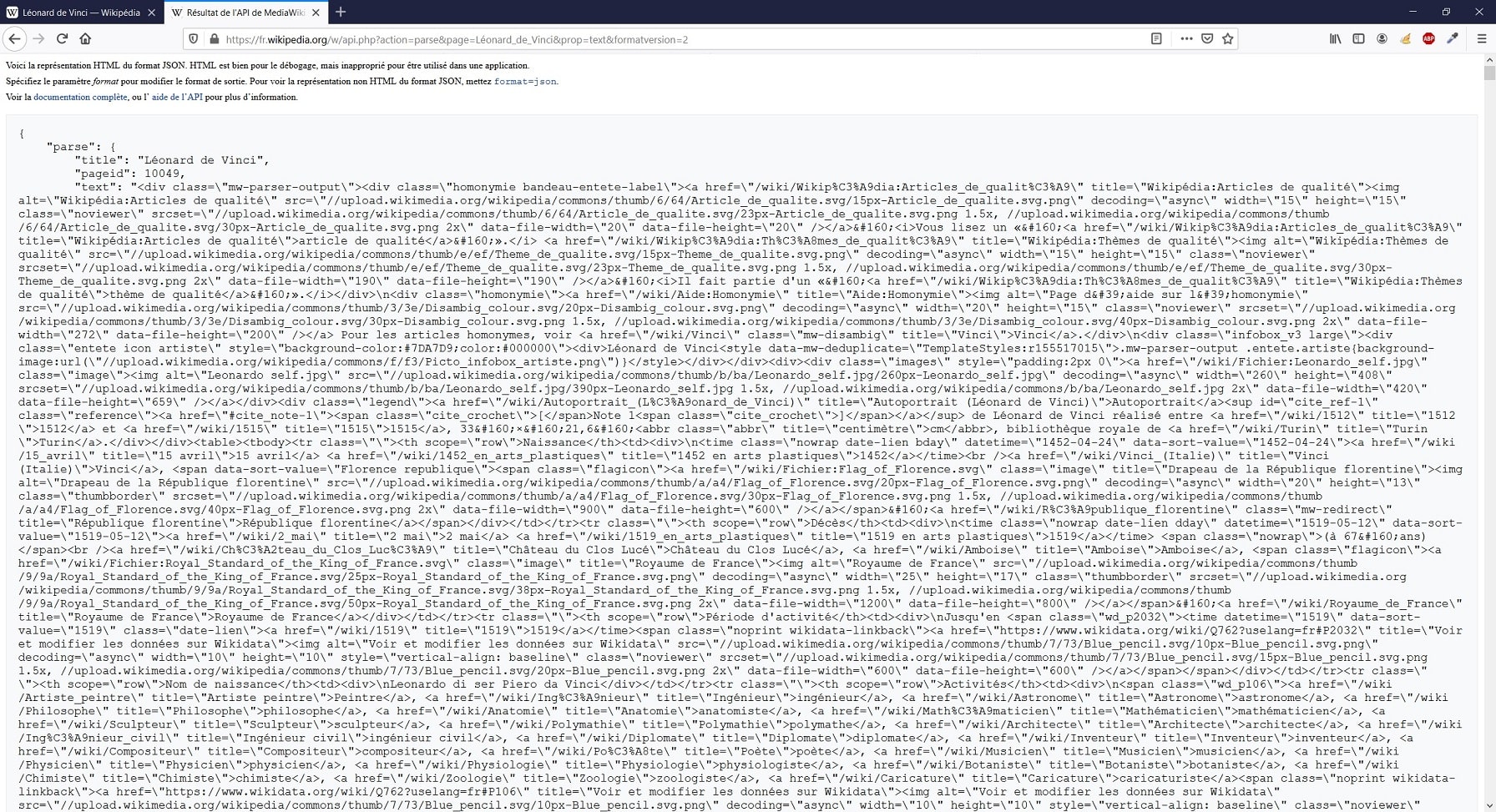
Il s’agit du contenu de l’article, mais délivré de façon brute, au format JSON.
Vous pouvez vous demander quel est l’intérêt de mettre en place un système comme celui-ci ? Les API ont avant tout été pensées pour les développeurs web, dans le but de faciliter leur travail. Ainsi, ce système permet de faciliter l’échange d’informations entre différents services sur le web. Nombreux sont les sites web qui choisissent également de mettre en place une API qui servira simplement d’arrière boutique. Ainsi, une fois que l’API contenant toutes les données est en place, la personne chargée de la construction du site web faisant lui office de « vitrine » n’aura pas besoin d’intégrer toutes les données qu’il souhaite afficher directement dans les pages. Il pourra simplement se contenter de structurer son code HTML, sa mise en forme CSS, et la donnée sera récupérée dynamiquement via l’API (par le biais, par exemple, d’appels AJAX). En termes de développement, cela représente donc un gain en flexibilité.
Nous précisons que l’API Wikipédia, que nous venons de prendre pour exemple, est une API ouverte. N’importe qui peut s’y connecter. De plus, elle accepte les requêtes en GET. Ce n’est clairement pas le cas de toutes les API. Beaucoup d’entre elles ne sont pas ouvertes au public, et demande ainsi à celui qui souhaite se connecter qu’il s’authentifie.
Il est essentiel de bien comprendre ce qu’est une API lorsque l’on souhaite pratiquer le web scraping. Car, vous l’aurez compris, si l’API facilite le travail du développeur web souhaitant récupérer de la donnée, il facilitera également le travail du web scraper. C’est la raison pour laquelle le premier point de notre méthodologie analytique consiste à savoir si le site que l’on souhaite scraper récupère la donnée affichée à partir d’une API, et, si c’est le cas, voir si nous pouvons nous même nous y connecter.
Bientôt la partie 2 de cet article, restez branchés...
Vous souhaitez bénéficier d'une formation présentielle en web scraping ? Vous pouvez probablement vous faire financer une de nos formations ! Pour en savoir plus téléchargez le programme de nos formations physiques.