
Définition
RAG est l’acronyme de “Retrieval Augmented Generation” (”génération à enrichissement contextuel” en français). Plus concrètement, en quoi cela consiste, et quelle en est l’utilité ? Imaginez que vous soyez le PDG d’une entreprise qui opère dans un secteur bien précis. Vos équipes sont amenées à travailler quotidiennement sur des sujets en lien avec votre secteur, et ses dernières avancées (évolutions liées à l’avancée de la recherche dans ce domaine, données et chiffres provenant de partenaires et clients, informations obtenues par le travail des équipes en interne…). L’utilisation classique d’outils d’Intelligence Artificielle, tels que ChatGPT ou Gemini, ne leur sera certainement d’aucune utilité dans le cadre de ce travail, car le travail d’analyse et de réflexion qu’elles doivent effectuer porte sur des sujets pointus, et des informations qui sont parfois privées, où n’étant pas diffusées sur le web de façon publique. Les outils d’IA n’ont donc, par défaut, pas accès à ces informations. C’est dans ce cas de figure que l’utilisation du RAG est pertinente. Le RAG consiste à créer une base de données vectorielle, dans laquelle on va insérer toute la donnée qui nous intéresse, pour ensuite connecter cette base à l’Agent IA de notre choix. Ainsi, cela permet de personnaliser son agent IA en lui fournissant toute la donnée spécifique qui va lui permettre de nous aider dans le cadre de notre réflexion sur des sujets bien précis. On prend souvent l’exemple des politiques RH internes d’une entreprise. Les outils IA par défaut n’ont pas accès à l’ensemble des informations liées à une entreprise, à ses salariés, etc. Elle n’y a pas accès, et d’ailleurs, il ne faudrait pas que ce soit le cas, car ces informations doivent rester privées ! Le RAG apporte une solution à ces deux problématiques : - il permet de créer un agent IA personnalisé et étant nourri par des informations et données qui nous intéressent - cet agent IA fonctionne dans un environnement privé et clos
Qu’est ce qu’une base de données vectorielle ?
Une base de données vectorielle est un type de base conçu pour stocker non pas du texte brut, mais des vecteurs, c’est-à-dire des représentations numériques qui encodent le sens d’un texte. Pour vulgariser, on peut imaginer qu’une IA traduit chaque morceau de texte en une longue liste de nombres, un peu comme si elle créait une “empreinte sémantique” permettant de comprendre le sujet, les mots-clés et le contexte. Pourquoi faire cela ? Parce que lorsqu’on pose une question à un agent IA, on souhaite qu’il retrouve les passages les plus pertinents, même si le vocabulaire employé n’est pas exactement le même. Les bases relationnelles classiques (SQL, par exemple) ne savent pas faire ce type de recherche “par sens”. Les bases vectorielles, elles, utilisent des calculs de similarité entre vecteurs pour identifier rapidement les morceaux de texte qui se rapprochent le plus de la demande de l’utilisateur. Le processus repose sur deux notions essentielles : - Les chunks : il s’agit de petits fragments de texte découpés à partir d’un document plus long. Chaque chunk doit être suffisamment grand pour avoir du sens, mais suffisamment petit pour être analysé efficacement. - Les embeddings : ce sont les vecteurs générés à partir de ces chunks. Un modèle d’IA lit le texte, en extrait les idées principales et produit une série de nombres permettant de le représenter mathématiquement. Une fois les embeddings stockés dans la base vectorielle, l’IA peut, lorsqu’elle reçoit une question, la convertir elle aussi en embedding, puis chercher les vecteurs les plus proches dans la base. Ce fonctionnement permet non seulement des recherches plus intelligentes que de simples mots-clés, mais aussi une adaptation naturelle au langage humain, aux synonymes, et aux formulations variées. C’est cette capacité qui fait des bases vectorielles un élément central dans tout système RAG.
Création d'un RAG dans n8n
La configuration d’un RAG demande initialement des compétences en développement IA. Avec n8n, il est désormais possible de créer un RAG sans avoir à coder. A ce sujet, n8n a justement crée un template informatif afin de montrer comment faire cela sur la plateforme.
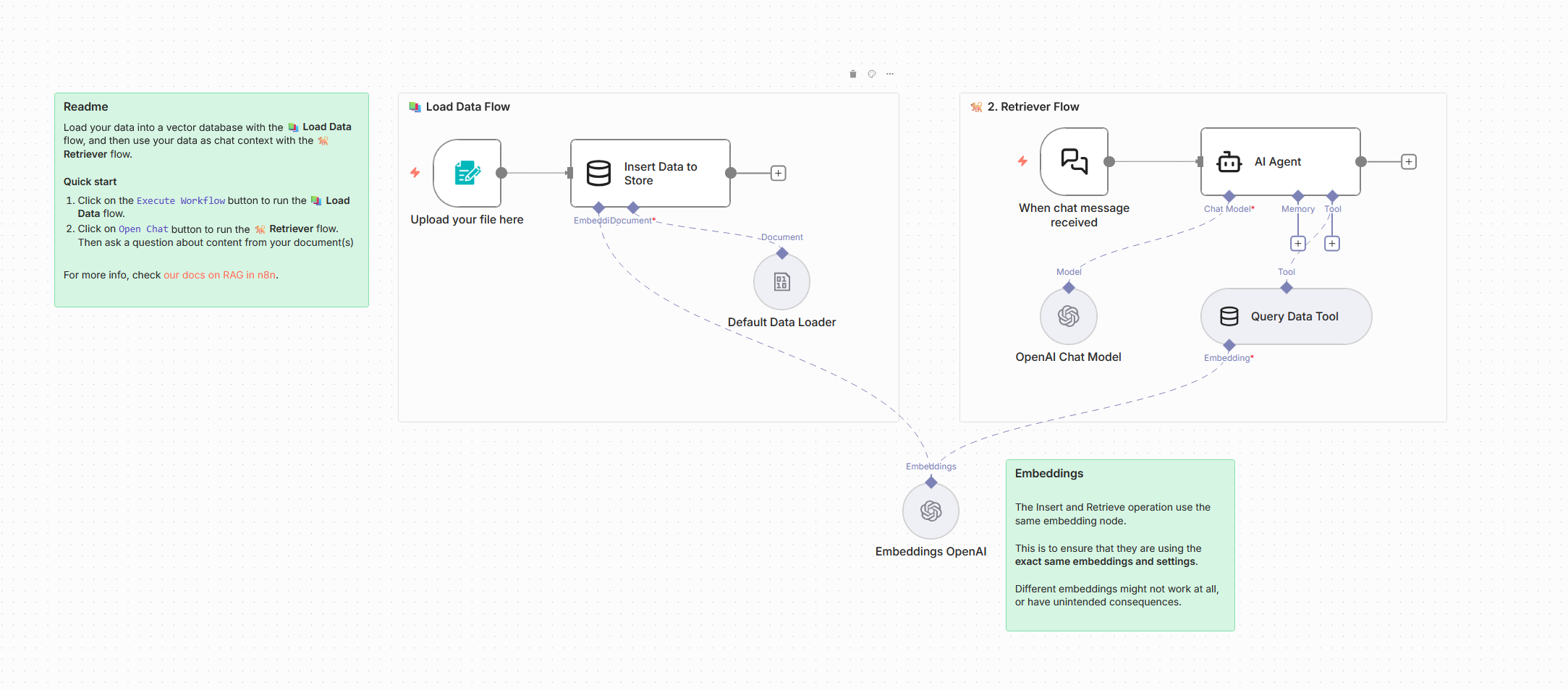
On a donc ici une première étape, à gauche, qui consiste à insérer de la donnée dans la base, et une seconde à droite, qui permet de mettre en place un chat, connecté à un agent IA, étant lui-même connecté à la base de donnée que l’on a nourrie. Les noeuds “Insert Data to Store” et “Query Data Tool” utilisés ici, proviennent de l’outil “Simple Vector Store”.
Il s’agit d’un outil natif de n8n qui permet de créer une base de donnée vectorielle stockée sur la plateforme. Comme le précise la documentation, cet outil a été pensé pour effectuer des tests. Si vous souhaitez mettre en place un RAG qui va ensuite être utilisé professionnellement, il faudra passer sur un des outils externes présents sur n8n et permettant la création d’un vectore store .
Il y a donc le choix entre différents outils. Dans le cadre du test que nous allons présenter ici, nous utiliserons Qdrant. Il s’agit d’un outil open-source, qui peut etre installé et personnalisé selon nos besoins, et nous permet de garder une indépendance totale (ce qui n’est pas le cas lorsqu’on utilise des outils tels que Supabase, Redis ou Pinecone, plus utilisés et plus faciles d’accès, mais qui sont des services externes dont on ne peut s’émanciper). Avant tout chose, on doit donc créer un compte sur Qdrant, récupérer notre clé API, et créer une nouvelle collection (base de données).
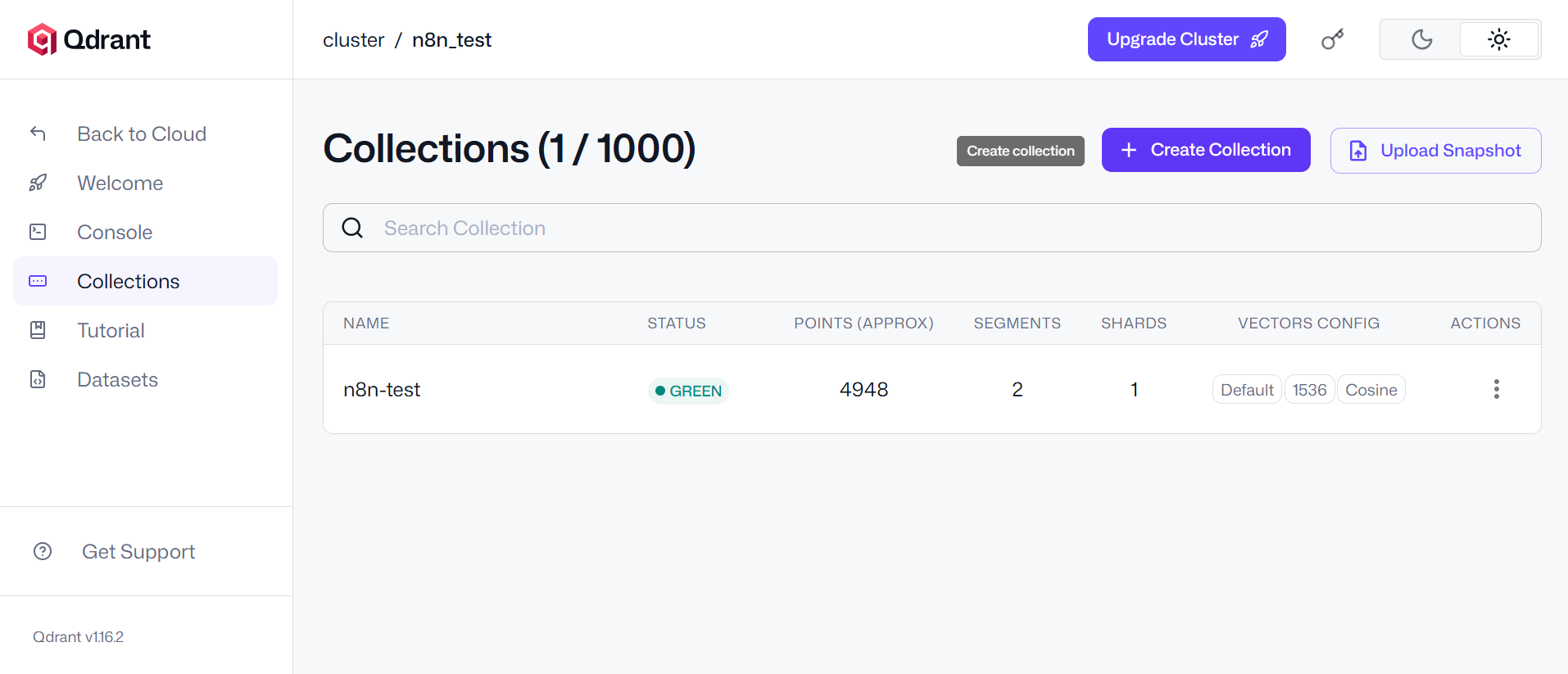
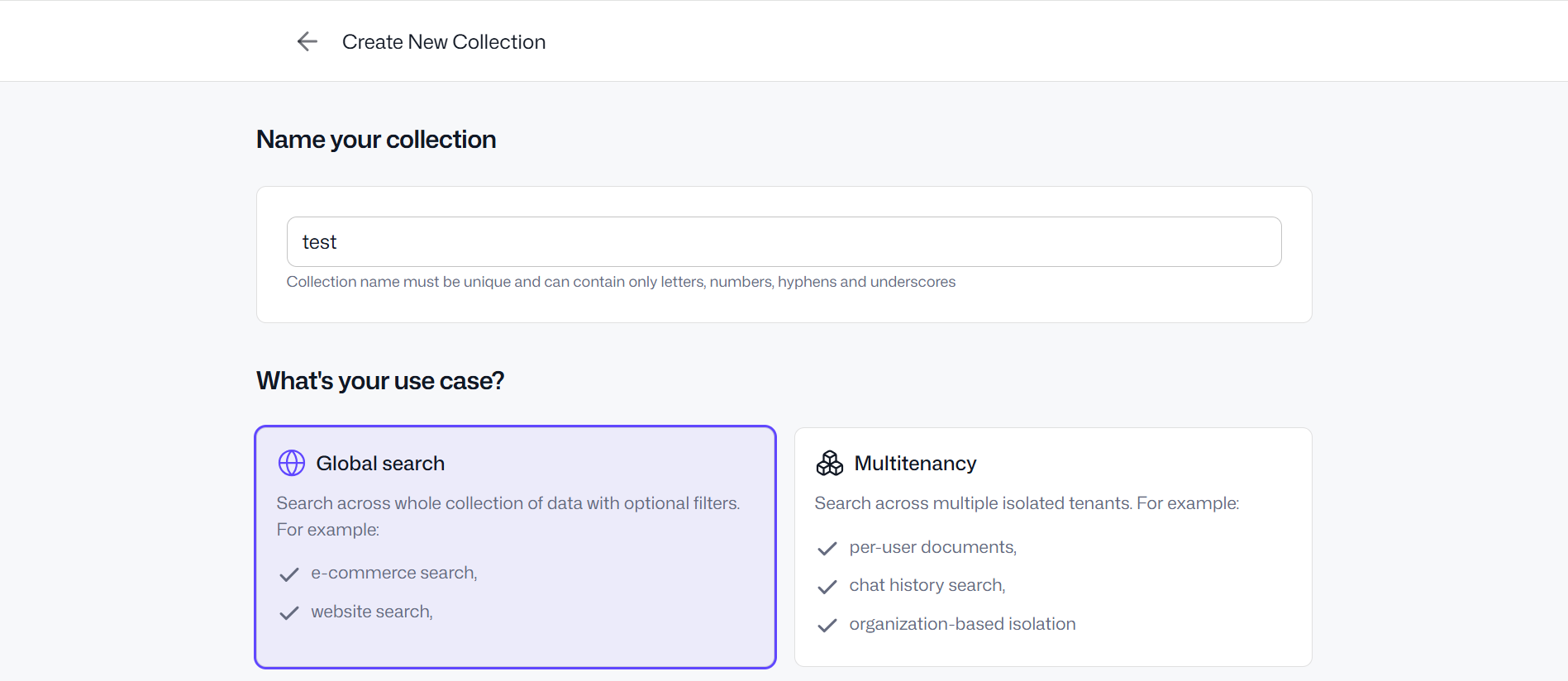
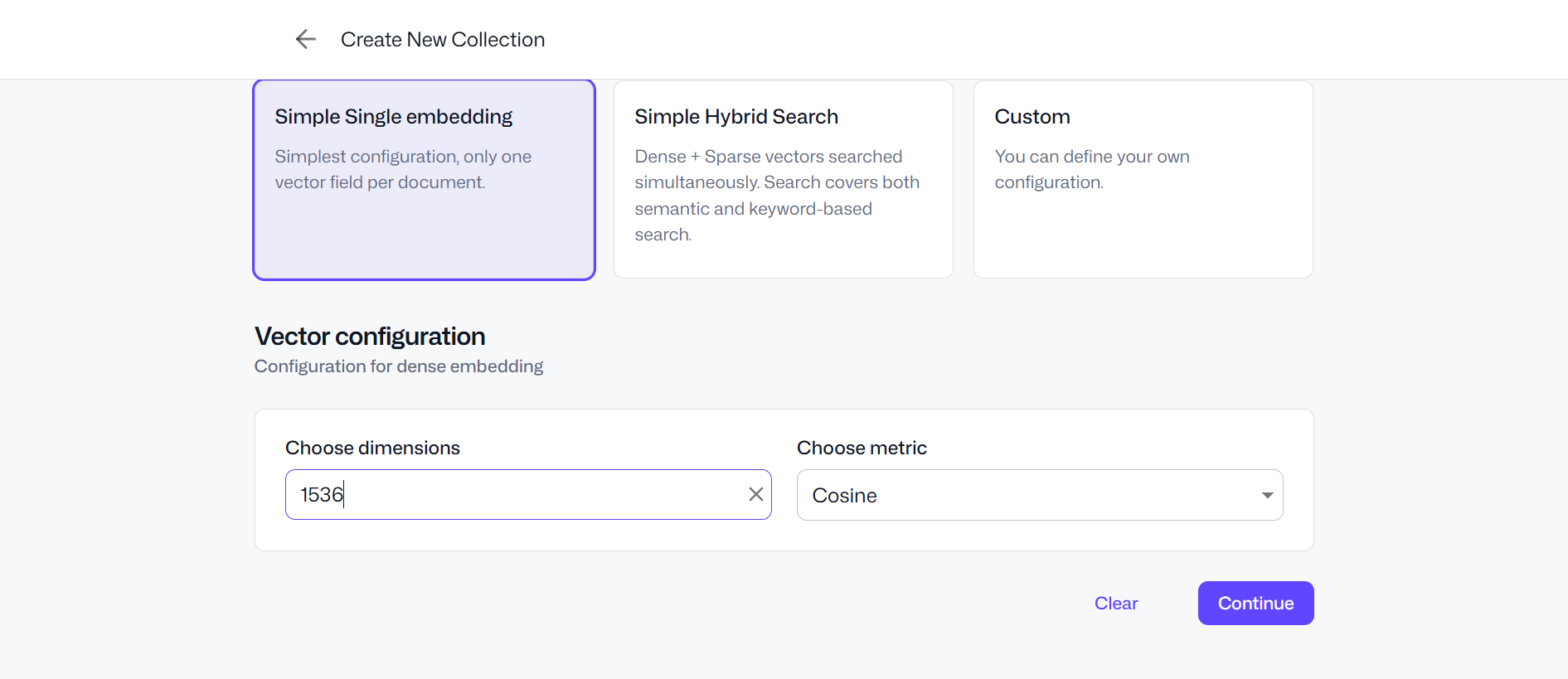
Utilisez les options par défaut telles que présentes sur les captures ci-dessus lors de la création de votre base de données de test. Coté n8n, en repartant du template initial, et en le personnalisant avec Qdrant, on obtient ce template :
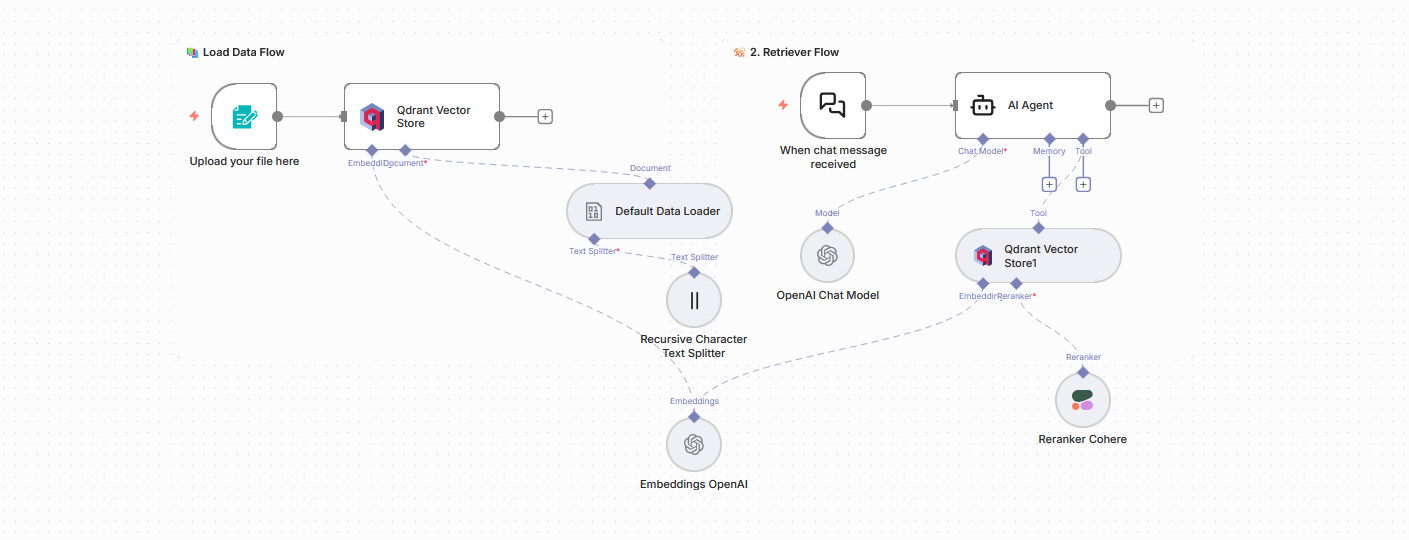
Voici le détail des étapes parcourues par le workflow :
Phase 1 (loading des données)
Noeud d’upload : charge un formulaire n8n permettant d’insérer un document (PDF, Word, image) qui sera ensuite envoyé vers la base de données vectorielle Noeud “Qdrant Vector Store”: se charge de l’insertion des données dans la base sélectionnée. Il faut créer les credentials à partir de la clé API récupérée sur Qdrant, sélectionner le mode “Insert Documents”, et sélectionner la base (collection) que l’on vient de créer. Comme on peut le voir sur le bas de la capture d’écran ci-dessous, ce noeud implique une liaison avec deux outils afin de pouvoir effectuer son travail correctement. Un outil “Embedding” et un outil “Document”.
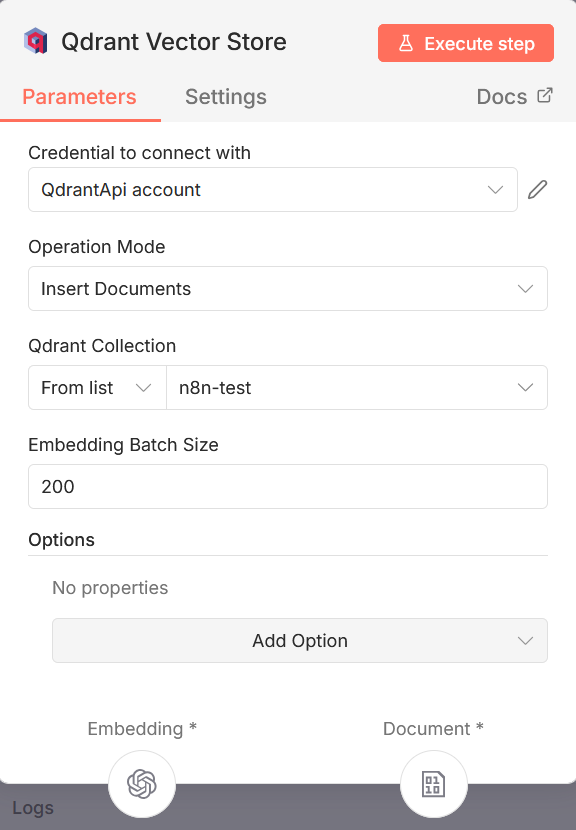
Noeud “Embedding OpenAI” : Il s’agit de l’outil embedding que nous avons sélectionné. L’outil embedding a pour rôle de convertir les chunks générés par l’outil “Document” en vecteurs, qui seront ensuite insérés dans la base Qdrant. Plusieurs IA proposent des services d’embedding (OpenAI, Ollama, Gemini, Cohere…). Noeud Document “Default data loader” : Il s’agit de l’outil “Document” lié au noeud Qdrant. Permet de définir la façon dont le document envoyé dans le premier noeud va etre découpé en chunks. Vous pouvez soit laisser le fonctionnement par défaut (Text splitting = Custom), soit choisir l’option custom pour personnaliser le splitting. Si cette option est activée, vous allez devoir connecter un noeud “Recursive character text splitter” afin de définir les options de customisation du splitting.
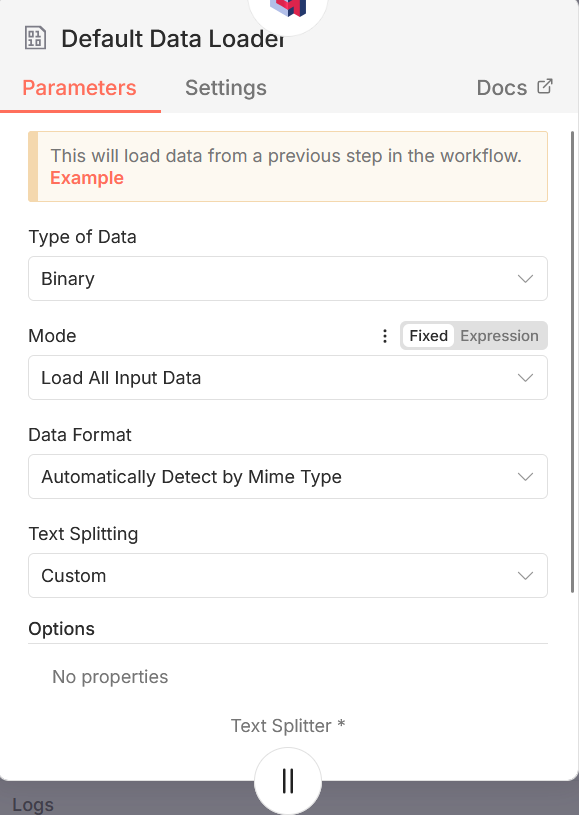
Noeud “Recursive character text splitter” : Ce noeud fonctionne de la façon suivante : il essaie de diviser le texte de façon progressive en testant plusieurs “séparateurs” — d’abord des sauts de paragraphe, puis des sauts de ligne, puis des phrases, puis en dernier recours des fragments plus petits — jusqu’à ce que chaque chunk respecte une taille (maximale) définie En d’autres termes : au lieu de couper arbitrairement chaque N caractères, il cherche la plus grande unité textuelle possible (para → phrase → mot) qui rentre dans la limite. Voici les deux paramètres qu’il permet de définir :
- Chunk size — la taille maximale d’un “chunk” (en nombre de caractères) avant de devoir couper. Par défaut (dans certains usages, comme le “Default Data Loader”), n8n met chunk_size = 1000 et un overlap = 200.
- Chunk overlap — le chevauchement (partie répétée) entre deux chunks successifs, pour préserver le contexte quand un chunk se termine et qu’un autre commence. Même si le splitter coupe, cela permet que l’information “au bord” ne soit pas perdue.
Phase 2 (Envoi des réponses)
Noeud “Chat” : créer un chat, pouvant être accessible via une URL publique, et qui transmet le texte qu’on y entre aux étapes suivantes du workflow.
Noeud “AI Agent” : il s’agit ici de l’agent IA au coeur de notre RAG. C’est lui qui récupère les questions reçues par le biais du chat, qui interroge la base de données Qdrant afin d’obtenir les éléments informationnelles lui permettant de construire sa réponse, et qui génère puis envoie cette réponse. Pour plus d’information sur le fonctionnement et la configuration d’un noeud AI AGent, voir notre article à ce sujet.
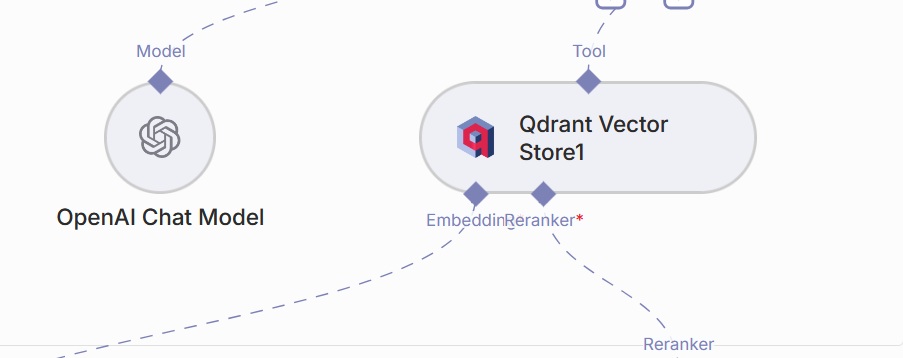
Noeud “Qdrant Vector Store” : noeud chargé de définir la façon dont l’Agent IA va interagir avec la base de données Qdrant. On y indique les instructions à passer à l’agent IA (Description), la base de donnée à utiliser (Qdrant Collection), le nombre maximum de résultats à récupérer (Limit), et si on souhaite inclure des Metadatas, et activer la fonctionnalité de reranking (voire noeud suivant).
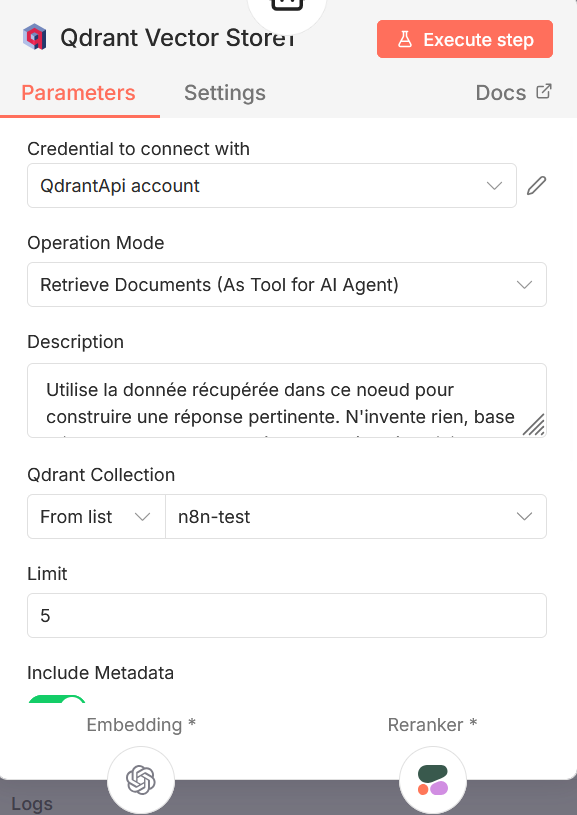
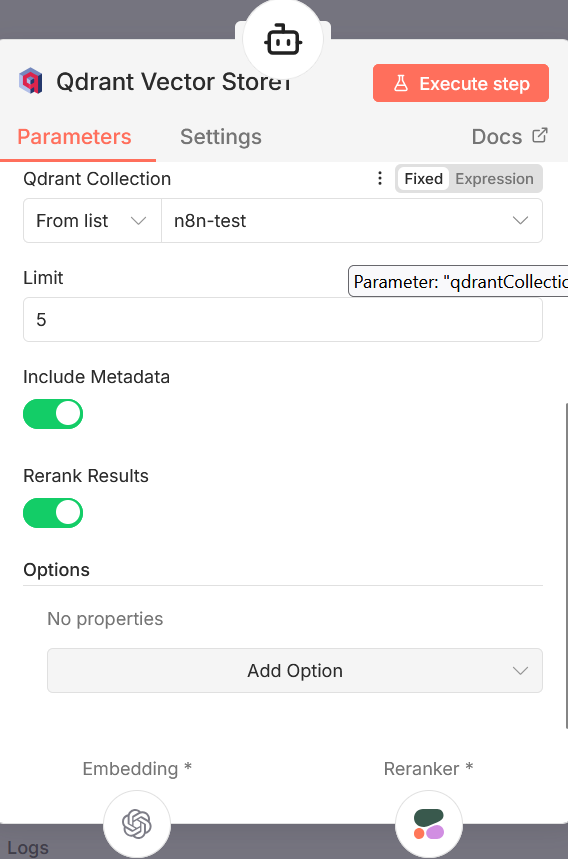
Noeud “Reranker Cohere” : le reranking est une technique qui peut être utilisée lorsqu’on souhaite optimiser le fonctionnement de son RAG. Lorsqu’une demande est envoyéé dans le chat, l’agent IA interroge la base vectorielle Qdrant. Celle-ci, par le biais du système d’indexation vectorielle, va renvoyer les *n* réponses qui lui semblent le mieux correspondre à la demande reçue (ce nombre *n* est définie par le paramètre “limit” que l’on a vu dans le noeud précédent). Le reranker Cohere va analyser ces *n* réponses, et les trier de façon à ce qu’elles soient bien classées par ordre de pertinence, ce qui améliore la précision de la réponse finale. Une fois ce workflow configuré, on peut désormais injecter plusieurs documents dans la base de données, et mettre en place un chatbot qui va pouvoir répondre à nos questions, de façon très spécialisées, et en se basant, par exemple, sur de la documentation interne.
Conclusion
La création d’un RAG est un moyen puissant de rendre une IA réellement utile dans un contexte professionnel, en lui donnant accès à des informations privées, ciblées et constamment mises à jour. Grâce à n8n, ce processus, autrefois réservé aux développeurs spécialistes de l’IA, devient accessible à tous grâce à un ensemble de nœuds simples à configurer et parfaitement intégrés. En combinant une base vectorielle comme Qdrant, un modèle d’embedding performant, et les nœuds IA d’n8n, on peut construire un agent capable d’interpréter des questions complexes, de parcourir intelligemment une grande quantité de documents internes, et de produire des réponses contextualisées, fiables et exploitables. Le RAG ouvre ainsi la voie à une nouvelle génération d’outils internes : assistants RH, copilotes métiers, moteurs de recherche documentaire intelligents, support client enrichi, et bien plus encore. Et surtout, il permet de garder la maîtrise totale des données, dans un environnement sécurisé et contrôlé.